FCNT(ICCV15)
Visual Tracking with Fully Convolutional Networks
作为应用CNN特征于物体跟踪的代表作品,FCNT的亮点之一在于对ImageNet上预训练得到的CNN特征在目标跟踪任务上的性能做了深入的分析,并根据分析结果设计了后续的网络结构。
FCNT主要对VGG-16的Conv4-3和Conv5-3层输出的特征图谱(feature map)做了分析,并得出以下结论:
(1) CNN 的feature map可以用来做跟踪目标的定位。
(2) CNN 的许多feature map存在噪声或者和物体跟踪区分目标和背景的任务关联较小。
(3) CNN不同层的特征特点不一。高层(Conv5-3)特征擅长区分不同类别的物体,对目标的形变和遮挡非常鲁棒,但是对类内物体的区分能力非常差。低层(Conv4-3)特征更关注目标的局部细节,可以用来区分背景中相似的distractor,但是对目标的剧烈形变非常不鲁棒。

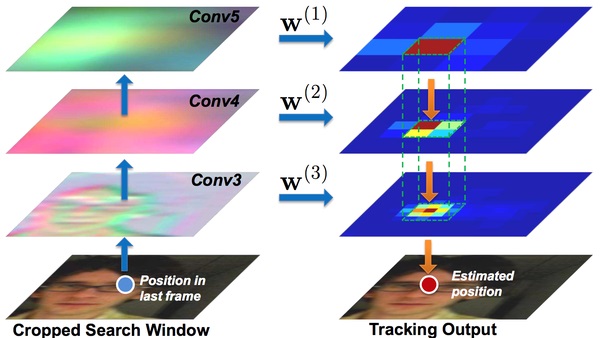
依据以上分析,FCNT最终形成了如上图所示的框架结构:
(1) 对于Conv4-3和Conv5-3特征分别构建特征选择网络sel-CNN(1层dropout加1层卷积),选出和当前跟踪目标最相关的feature map channel。
(2) 对筛选出的Conv5-3和Conv4-3特征分别构建捕捉类别信息的GNet和区分distractor(背景相似物体)的SNet(都是两层卷积结构)。
(3) 在第一帧中使用给出的bounding-box生成热度图(heat map)回归训练sel-CNN, GNet和SNet。
(4) 对于每一帧,以上一帧预测结果为中心crop出一块区域,之后分别输入GNet和SNet,得到两个预测的heatmap,并根据是否有distractor决定使用哪个heatmap 生成最终的跟踪结果。
小结:FCNT根据对CNN不同层特征的分析,构建特征筛选网络和两个互补的heat-map预测网络。达到有效抑制distractor防止跟踪器漂移,同时对目标本身的形变更加鲁棒的效果,也是ensemble思路的又一成功实现。在CVPR2013提出的OTB50数据集上OPE准确度绘图(precision plot)达到了0.856,OPE成功率绘图(success plot)达到了0.599,准确度绘图有较大提高。实际测试中FCNT的对遮挡的表现不是很鲁棒,现有的更新策略还有提高空间。
Hierarchical Convolutional Features for Visual Tracking(ICCV15)
这篇是作者在2015年度看到的最简洁有效的利用深度特征做跟踪的论文。其主要思路是提取深度特征,之后利用相关滤波器确定最终的bounding-box。
这篇论文简要分析了VGG-19特征( Conv3_4, Conv4_4, Conv5_4 )在目标跟踪上的特性,得出的结论和FCNT有异曲同工之处,即:
(1) 高层特征主要反映目标的语义特性,对目标的表观变化比较鲁棒。
(2) 低层特征保存了更多细粒度的空间特性,对跟踪目标的精确定位更有效。
基于以上结论,作者给出了一个粗粒度到细粒度(coarse-to-fine)的跟踪算法即:
(1) 第一帧时,利用Conv3_4,Conv4_4,Conv5_4特征的插值分别训练得到3个相关滤波器。
(2) 之后的每帧,以上一帧的预测结果为中心crop出一块区域,获取三个卷积层的特征,做插值,并通过每层的相关滤波器预测二维的confidence score。
(3) 从Conv5_4开始算出confidence score上最大的响应点,作为预测的bounding-box的中心位置,之后以这个位置约束下一层的搜索范围,逐层向下做更细粒度的位置预测,以最低层的预测结果作为最后输出。具体公式如下:

(4) 利用当前跟踪结果对每一层的相关滤波器做更新。
小结:这篇文章针对VGG-19各层特征的特点,由粗粒度到细粒度最终准确定位目标的中心点。在CVPR2013提出的OTB50数据集上OPE准确度绘图达到了0.891,OPE成功率绘图达到了0.605,相较于FCNT和SO-DLT都有提高,实际测试时性能也相当稳定,显示出深度特征结合相关滤波器的巨大优势。但是这篇文章中的相关滤波器并没有对尺度进行处理,在整个跟踪序列中都假定目标尺度不变。在一些尺度变化非常剧烈的测试序列上如CarScale上最终预测出的bounding-box尺寸大小和目标本身大小相差较大。
以上两篇文章均是应用预训练的CNN网络提取特征提高跟踪性能的成功案例,说明利用这种思路解决训练数据缺失和提高性能具有很高的可行性。但是分类任务预训练的CNN网络本身更关注区分类间物体,忽略类内差别。目标跟踪时只关注一个物体,重点区分该物体和背景信息,明显抑制背景中的同类物体,但是还需要对目标本身的变化鲁棒。分类任务以相似的一众物体为一类,跟踪任务以同一个物体的不同表观为一类,使得这两个任务存在很大差别,这也是两篇文章融合多层特征来做跟踪以达到较理想效果的动机所在。
利用跟踪序列预训练,在线跟踪时微调
1和2中介绍的解决训练数据不足的策略和目标跟踪的任务本身存在一定偏离。有没有更好的办法呢?VOT2015冠军MDNet给出了一个示范。该方法在OTB50上也取得了OPE准确度绘图0.942,OPE成功率绘图0.702的惊人得分。

