
重建效果上,用PSNR指标看来ESPCN比SRCNN要好一些。对于1080HD的视频图像,做放大四倍的高分辨率重建,SRCNN需要0.434s而ESPCN只需要0.029s。

4, VESPCN
在视频图像的SR问题中,相邻几帧具有很强的关联性,上述几种方法都只在单幅图像上进行处理,而VESPCN( Real-Time Video Super-Resolution with Spatio-Temporal Networks and Motion Compensation, arxiv 2016)提出使用视频中的时间序列图像进行高分辨率重建,并且能达到实时处理的效率要求。其方法示意图如下,主要包括三个方面:

一是纠正相邻帧的位移偏差,即先通过Motion estimation估计出位移,然后利用位移参数对相邻帧进行空间变换,将二者对齐。二是把对齐后的相邻若干帧叠放在一起,当做一个三维数据,在低分辨率的三维数据上使用三维卷积,得到的结果大小为r2 x H x W。三是利用ESPCN的思想将该卷积结果重新排列得到大小为1 x rH x rW的高分辨率图像。
Motion estimation这个过程可以通过传统的光流算法来计算,DeepMind 提出了一个Spatial Transformer Networks, 通过CNN来估计空间变换参数。VESPCN使用了这个方法,并且使用多尺度的Motion estimation:先在比输入图像低的分辨率上得到一个初始变换,再在与输入图像相同的分辨率上得到更精确的结果,如下图所示:
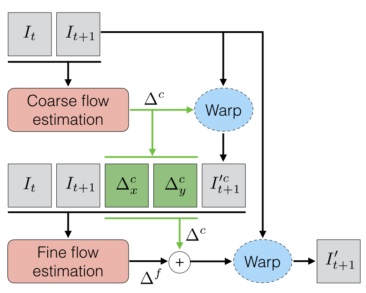
由于SR重建和相邻帧之间的位移估计都通过神经网路来实现,它们可以融合在一起进行端到端的联合训练。为此,VESPCN使用的损失函数如下:

第一项是衡量重建结果和金标准之间的差异,第二项是衡量相邻输入帧在空间对齐后的差异,第三项是平滑化空间位移场。下图展示了使用Motion Compensation 后,相邻帧之间对得很整齐,它们的差值图像几乎为0.

从下图可以看出,使用了Motion Compensation,重建出的高分辨率视频图像更加清晰。

5, SRGAN
SRGAN (Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network, , 21 Nov, 2016)将生成式对抗网络(GAN)用于SR问题。其出发点是传统的方法一般处理的是较小的放大倍数,当图像的放大倍数在4以上时,很容易使得到的结果显得过于平滑,而缺少一些细节上的真实感。因此SRGAN使用GAN来生成图像中的细节。
传统的方法使用的代价函数一般是最小均方差(MSE),即

该代价函数使重建结果有较高的信噪比,但是缺少了高频信息,出现过度平滑的纹理。SRGAN认为,应当使重建的高分辨率图像与真实的高分辨率图像无论是低层次的像素值上,还是高层次的抽象特征上,和整体概念和风格上,都应当接近。整体概念和风格如何来评估呢?可以使用一个判别器,判断一副高分辨率图像是由算法生成的还是真实的。如果一个判别器无法区分出来,那么由算法生成的图像就达到了以假乱真的效果。
因此,该文章将代价函数改进为

第一部分是基于内容的代价函数,第二部分是基于对抗学习的代价函数。基于内容的代价函数除了上述像素空间的最小均方差以外,又包含了一个基于特征空间的最小均方差,该特征是利用VGG网络提取的图像高层次特征:

对抗学习的代价函数是基于判别器输出的概率:

其中DθD()是一个图像属于真实的高分辨率图像的概率。GθG(ILR)是重建的高分辨率图像。SRGAN使用的生成式网络和判别式网络分别如下:
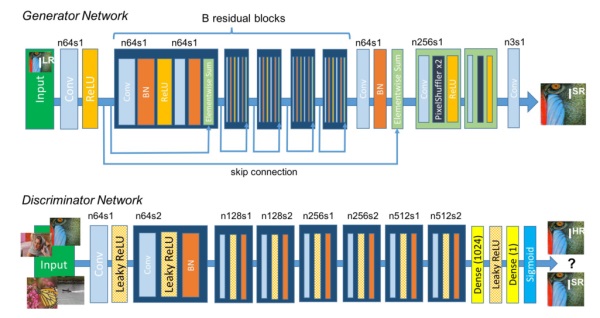
该方法的实验结果如下


