小小将:足够大的参数+好的训练方法,三层神经网络可以逼近任何一个非线性函数
先简单来看一下transformer在分类,检测和分割上的应用:
(1)分类 ViT: An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
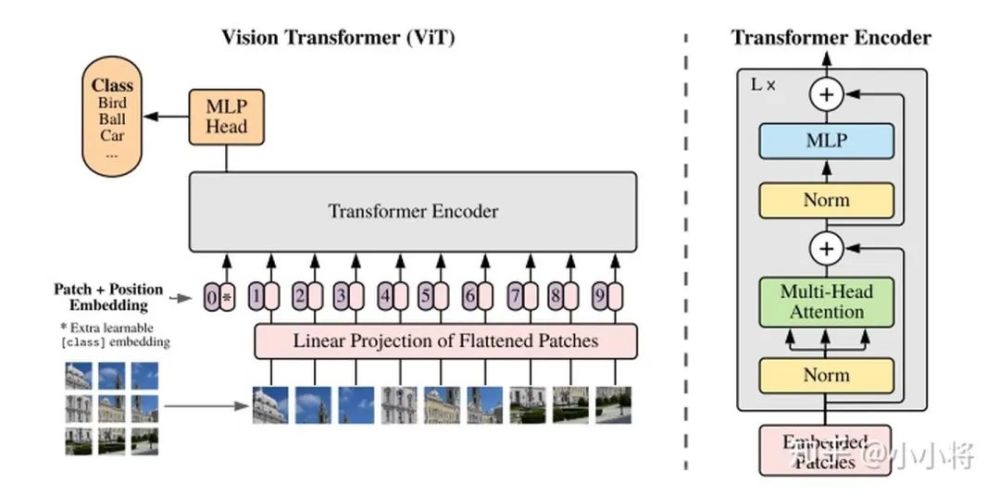
把图像分成固定大小的patchs,把patchs看成words送入transformer的encoder,中间没有任何卷积操作,增加一个class token来预测分类类别。
(2)检测 DETR:End-to-End Object Detection with Transformers
先用CNN提取特征,然后把最后特征图的每个点看成word,这样特征图就变成了a sequence words,而检测的输出恰好是a set objects,所以transformer正好适合这个任务。n0609
(3)分割 SETR:Rethinking Semantic Segmentation from a Sequence-to-Sequence Perspective with Transformers
用ViT作为的图像的encoder,然后加一个CNN的decoder来完成语义图的预测。
当然,目前基于transformer的模型在分类,检测和分割上的应用绝不止上面这些,但基本都是差不多的思路。
比如ViT-FRCNN:Toward Transformer-Based Object Detection这个工作是把ViT和RCNN模型结合在一起来实现检测的。
关于transformer更多在CV上的工作,可以看最新的一篇综述文章:A Survey on Visual Transformer

