然后是梯度计算,请上Sobel kernel,我们定义一个计算纵向梯度的核,如果一个像素点的纵向梯度非常大,那么这个点的结果会非常大:
- sobelConv = ConvLayer(1,1,3)
- sobelConv.w[0,0] = np.array([[-1,-2,-1],[0,0,0],[1,2,1]])
- sobel_out = sobelConv.forward(in_data)
- plt.imshow(sobel_out[0], cmap='Greys_r')
图像结果如下所示:
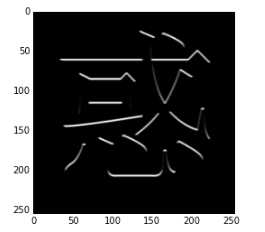
从结果来看,文字中横向比划的上端被保留了下来。
最后来一张Gabor filter的效果,现在的一些论文里面都宣称自己的模型能够学出Gabor filter的参数来(Gabor filter代码来自wikipedia):
- def gabor_fn(sigma, theta, Lambda, psi, gamma):
- sigma_x = sigma
- sigma_y = float(sigma) / gamma
- (y, x) = np.meshgrid(np.arange(-1,2), np.arange(-1,2))
- # Rotation
- x_theta = x * np.cos(theta) + y * np.sin(theta)
- y_theta = -x * np.sin(theta) + y * np.cos(theta)
- gb = np.exp(-.5 * (x_theta ** 2 / sigma_x ** 2 + y_theta ** 2 / sigma_y ** 2)) * np.cos(2 * np.pi / Lambda * x_theta + psi)
- return gb
- print gabor_fn(2, 0, 0.3, 0, 2)
- gaborConv = ConvLayer(1,1,3)
- gaborConv.w[0,0] = gabor_fn(2, 0, 0.3, 1, 2)
- gabor_out = gaborConv.forward(in_data)
- plt.imshow(gabor_out[0], cmap='Greys_r')
- [[-0.26763071 -0.44124845 -0.26763071]
- [ 0.60653066 1. 0.60653066]
- [-0.26763071 -0.44124845 -0.26763071]]
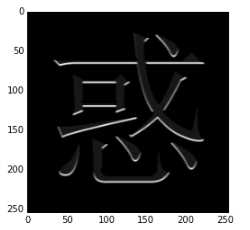
从结果可以看出,Gabor filter同样可以做到边缘提取的作用,这和它本身的功能是相符的。
好了,以上三种处理完成之后,我们可以看出,不同的滤波核确实能起到不同的效果。实际上用于图像滤波的卷积核还有很多。
下面要试图做一些讲道理的事情,也就是说明:
- 为什么要发明卷积层这种神经层?能不能用全连接层代替卷积层?
很显然,用全连接层代替卷积层是完全没有问题的,但是这样做的代价实在太大了。原始图像的维度相对而言比较大,如果采用全连接的话参数将会有爆炸式的增长,参数的数量可能对于现在的电脑来说是一个灾难。试想一下对于MNist的数据,如果第一层是全连接层,即使把1*28*28数据映射到1*1024这样的输出上,其中的参数已经达到800万。而曾经的经典模型Lenet呢?

从上面的图可以看出(此处):
第一层卷积的参数数量为:1*6*(5*5+1)=156,却可以得到6*28*28的输出。
两者的参数数量差距几万倍,而实际上两者效果绝对不会有如此大的差距。
既然如此,参数数量如此少的卷积层为什么可以有用?识别这样的问题总体来说是一种比较宏观的问题。像MNist这样的问题,每张图片上有784个像素,理论上可以有256^{784}种组合,而实际的类别只有10种,基本上可以断定提供的信息是远远多于满足搜索需求的数量的。那么多出来的像素信息是以什么样的形式展现呢?在图像处理上,有一个词叫“局部相关性”就是指这样的问题。
我们是如何识别出一个数字的呢?当然是因为这个数字不同于别的数字的特点,对于像MNist这样的数据,特点自然来自于明暗交界的地方。一片黑的区域不会告诉我们任何有用的信息,同样地,一片白的区域也不会告诉我们任何有用的信息。同样,数字的笔画粗细对我们的识别也没有太大的作用。这些都是我们识别过程中会遇到的问题,而其中临近像素之间有规律地出现相似的状态就是局部相关性。
那么如何消除这些局部相关性呢,使我们的特征变得少而精呢?卷积就是一种很好地方法。它只考虑附近一块区域的内容,分析这一小片区域的特点,这样针对小区域的算法可以很容易地分析出区域内的内容是否相似。如果再加上Pooling层(可以理解为汇集,聚集的意思,后面不做翻译),从附近的卷积结果中再采样选择一些高价值的合成信息,丢弃一些重复低质量的合成信息,就可以做到对特征信息的进一步处理过滤,让特征向少而精的方向前进。

