看完了给下一层传导的loss,下面是本层的参数导数。和之前类似,我们需要重新整理运算关系。同样地,我们再来一张图进行解释:
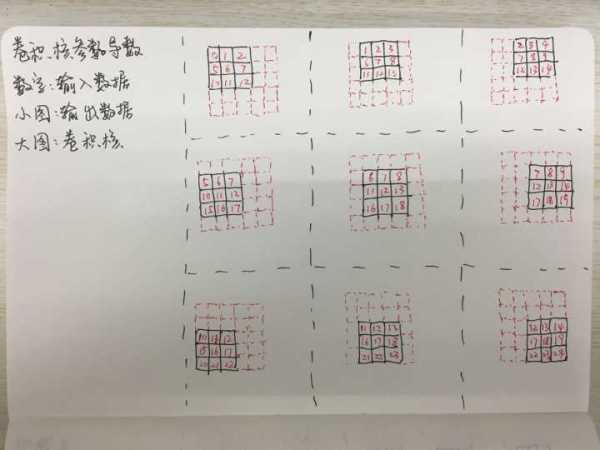
从这张图又可以很清楚地看出这个关系。这一次我们直接把输入数据和输出数据的残差做卷积,就可以得到参数w的导数。比上面的计算还要简单点。这里的求解也只需要一步就可以:
residual_w=conv2(x,residual_z) 实际上到此为止,卷积层的实力解法就到此结束了,实际上它与全连接层最大的不同就是线性部分,关于非线性部分的事情我们后面再说,但是由于线性部分和非线性部分相互独立,因此分来分析也是完全没有问题的。
所以从上面的分析中可以看出,想要采用实力派的解法需要能够清晰地画出下面三张图:
- 前向图:标有卷积核id->的输入小图->组成的输出大图
- 下层Loss:标有卷积核id->的输出小图->组成的输入大图
- 本层w导数:标有输入id->的输出小图->组成的卷积核大图
刚才看到的是stride=1,padding=0的解法,相对来说省略了一些细节的考虑。如果把这些加上,这种方法也是可以解的,只不过比刚才要复杂一些。这里就不做更进一步的推导了,有志成为“实力派”的童鞋可以去尝试一下进一步地推导。但不管做怎么样的变换,都离不开上面三张图的推导。熟练推导三张图能够让我们更加深刻地理解卷积(相关)操作内部的过程,是绝对有好处的。
“偶像派”解法
说实话,像神经网络里面这样的推导所涉及到的数学能力并不高,但是想熟练掌握需要好好地刷一刷。但是如果不想把自己搞得这么痛苦,就可以试试偶像派的解法。
偶像派的解法是怎么做到的呢?我们前面说了卷积层的卷积计算是线性的,既然是线性的我们能不能把输入矩阵做一个变换,使运算变成一个矩阵和卷积核向量相乘的运算呢?当然可以了,这就涉及到我们的“整容”过程了。
整容的过程只需要用到上面的第一张图——前向图。前向图中每一个小图都可以表示输入数据的一部分和卷积核做点积的过程。最终我们求出了9个结果值,因此也就有9个输入的部分数据和卷积做了点积。这个过程同样可以画成一张图:

这样看来,前向计算和求解卷积核参数导数的计算就会变得容易得多。不过如果考虑了padding和stride,写这个转换的算法还是需要点细心的。至于向下一层传递的导数,做法也类似,转成矩阵乘法的形式即可,这里就不再赘述了。
这样,偶像派的解法也就完成了。借助了矩阵和向量的乘法,我们的大脑得到了极大的解放。那么问题来了,对于我们常用的软件库,大家是怎么实现这个算法的呢?
基本上大家都选择偶像的道路……倒不是因为偶像派的思路清晰,而是因为矩阵乘法这样的运算经过大家多年的研究,运算效率非常有保障。而卷积运算在实现过程中像cache友好性这样的问题会差些,所以最终被淘汰。
当然,现在被广大群众所爱戴的——CUDNN库的实现比我们偶像派的做法在细节上更为精细,可以算是偶像+实力兼备。感兴趣的童鞋可以去了解一下。
聊完了线性部分求解的事情,下次就来一起看看非线性部分的一些问题。

