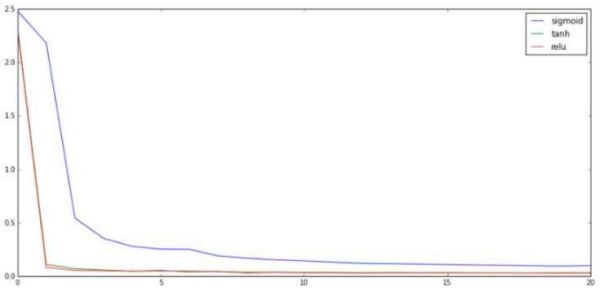
这个图的效果和前面的训练图类似。看到这里我们可以确定:对于这个问题,在其他变量保持一致的情况下,使用sigmoid的非线性函数训练效果会若些。那么上面提到的参数训练的问题呢?
关于观测参数更新这个问题,caffe已经为我们想好了。在solver配置文件中加入下面这一行配置就可以查看前向后向的数据和参数信息了:
debug_info: true 这里我们主要关注的是后向的参数。后向为我们展示的是bottom_data的diff和param的diff。这里我们主要关注的是param的diff,因为这是最终落到参数更新上的数量。Debug信息显示的是同一个参数的平均值。虽然是平均值,但是它也有一定的价值,而它也足以分析出问题来。
首先是sigmoid的四个主要层的参数更新量:

从图中可以明显看出一个规律,那就是越靠上的层参数更新的量越大,越靠下的参数更新量越小。这和我们刚才的描述是一致的。那么其他的函数表现如何呢?接下来是tanh的:
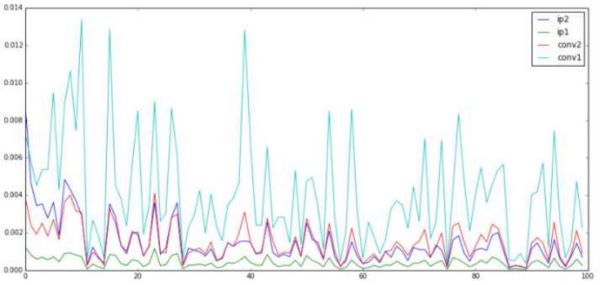
可以看出tanh的参数更新整体上好了许多。最起码不是越靠上越大了,这也说明在这个问题中tanh不存在梯度消失的问题,那么relu呢?

relu的结果同样没有出现梯度消失的问题,而且它的四条线距离和tanh相比更相近一些。
通过上面的分析,我们发现了sigmoid确实不适合深度学习模型,虽然它的函数曲线和人的神经反应很相似,但是在深度学习上它确实不太好用。这也是件无可奈何的事情,不过它还是在很多浅层模型上发挥着巨大的作用,所以它不会离开我们的视线的。
计算简单
关于这个部分……我想就不用多说了。上面表现良好的tanh和relu,哪个好算大家一目了然。在效果相近的情况下,自然是选择简单的函数。
稀疏性
很多前辈在提到了relu时,同时提到了它的稀疏性。因为它强行把小于0的部分截断,这样数据中就会出现很多0。这些0再乘以任何数都等于0,无形中相当于减少了数据的维度。再小的数据也比不上一个0来的实在,如果配上CNN中另一个重量级元素max pooling层,可以把这些为0的数据直接清除掉,这样数据的维度就可以进一步地压缩了。
relu函数还有一个很奇特的地方,那就是它看上去是一个非线性层,实际上操作起来却有点像一个线性层。对于线性部分的输出,最终的结果就好像左乘一个非0即1的对角阵:
前面在分析非线性层的作用中,曾经有一条就是它使得深层网络变得有意义。这一点relu是可以做到的。但是它的效果还是像把输入数据做了线性投影一样,而不是非线性变换。relu看上去简单,可是实际上它能够在复杂的网络中有一席之地,还是有它存在的道理的。当然它也有它的问题,关于它的问题以后再说。
卷积层的基本结构也就到这了,后面内容更精彩~

