如果size
通过组合可以得出四种基本窗口
time-tumbling-window 无重叠数据的时间窗口,设置方式举例:timeWindow(Time.seconds(5))
time-sliding-window 有重叠数据的时间窗口,设置方式举例:timeWindow(Time.seconds(5), Time.seconds(3))
count-tumbling-window无重叠数据的数量窗口,设置方式举例:countWindow(5)
count-sliding-window 有重叠数据的数量窗口,设置方式举例:countWindow(5,3)
3) Window Reduce
WindowedStream → DataStream:给window赋一个reduce功能的函数,并返回一个聚合的结果。
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.api.scala._
import org.apache.flink.streaming.api.windowing.time.Time
object StreamWindowReduce {
def main(args: Array[String]): Unit = {
// 获取执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
// 创建SocketSource
val stream = env.socketTextStream("node01", 9999)
// 对stream进行处理并按key聚合
val streamKeyBy = stream.map(item => (item, 1)).keyBy(0)
// 引入时间窗口
val streamWindow = streamKeyBy.timeWindow(Time.seconds(5))
// 执行聚合操作
val streamReduce = streamWindow.reduce(
(item1, item2) => (item1._1, item1._2 + item2._2)
)
// 将聚合数据写入文件
streamReduce.print()
// 执行程序
env.execute("TumblingWindow")
}
}
4) Window Apply
apply方法可以进行一些自定义处理,通过匿名内部类的方法来实现。当有一些复杂计算时使用。
用法
实现一个 WindowFunction 类指定该类的泛型为 [输入数据类型, 输出数据类型, keyBy中使用分组字段的类型, 窗口类型]
示例:使用apply方法来实现单词统计
步骤:
获取流处理运行环境构建socket流数据源,并指定IP地址和端口号对接收到的数据转换成单词元组使用 keyBy 进行分流(分组)使用 timeWinodw 指定窗口的长度(每3秒计算一次)实现一个WindowFunction匿名内部类apply方法中实现聚合计算使用Collector.collect收集数据
核心代码如下:
//1. 获取流处理运行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
//2. 构建socket流数据源,并指定IP地址和端口号
val textDataStream = env.socketTextStream("node01", 9999).flatMap(_.split(" "))
//3. 对接收到的数据转换成单词元组
val wordDataStream = textDataStream.map(_->1)
//4. 使用 keyBy 进行分流(分组)
val groupedDataStream: KeyedStream[(String, Int), String] = wordDataStream.keyBy(_._1)
//5. 使用 timeWinodw 指定窗口的长度(每3秒计算一次)
val windowDataStream: WindowedStream[(String, Int), String, TimeWindow] = groupedDataStream.timeWindow(Time.seconds(3))
//6. 实现一个WindowFunction匿名内部类
val reduceDatStream: DataStream[(String, Int)] = windowDataStream.apply(new RichWindowFunction[(String, Int), (String, Int), String, TimeWindow] {
//在apply方法中实现数据的聚合
override def apply(key: String, window: TimeWindow, input: Iterable[(String, Int)], out: Collector[(String, Int)]): Unit = {
println("hello world")
val tuple = input.reduce((t1, t2) => {
(t1._1, t1._2 + t2._2)
})
//将要返回的数据收集起来,发送回去
out.collect(tuple)
}
})
reduceDatStream.print()
env.execute()
5) Window Fold
WindowedStream → DataStream:给窗口赋一个fold功能的函数,并返回一个fold后的结果。
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.api.scala._
import org.apache.flink.streaming.api.windowing.time.Time
object StreamWindowFold {
def main(args: Array[String]): Unit = {
// 获取执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
// 创建SocketSource
val stream = env.socketTextStream("node01", 9999,'',3)
// 对stream进行处理并按key聚合
val streamKeyBy = stream.map(item => (item, 1)).keyBy(0)
// 引入滚动窗口
val streamWindow = streamKeyBy.timeWindow(Time.seconds(5))
// 执行fold操作
val streamFold = streamWindow.fold(100){
(begin, item) =>
begin + item._2
}
// 将聚合数据写入文件
streamFold.print()
// 执行程序
env.execute("TumblingWindow")
}
}
6) Aggregation on Window
WindowedStream → DataStream:对一个window内的所有元素做聚合操作。min和 minBy的区别是min返回的是最小值,而minBy返回的是包含最小值字段的元素(同样的原理适用于 max 和 maxBy)。
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.streaming.api.windowing.time.Time
import org.apache.flink.api.scala._
object StreamWindowAggregation {
def main(args: Array[String]): Unit = {
// 获取执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
// 创建SocketSource
val stream = env.socketTextStream("node01", 9999)
// 对stream进行处理并按key聚合
val streamKeyBy = stream.map(item => (item.split(" ")(0), item.split(" ")(1))).keyBy(0)
// 引入滚动窗口
val streamWindow = streamKeyBy.timeWindow(Time.seconds(5))
// 执行聚合操作
val streamMax = streamWindow.max(1)
// 将聚合数据写入文件
streamMax.print()
// 执行程序
env.execute("TumblingWindow")
}
}
4. EventTime与Window1) EventTime的引入与现实世界中的时间是不一致的,在flink中被划分为事件时间,提取时间,处理时间三种。如果以EventTime为基准来定义时间窗口那将形成EventTimeWindow,要求消息本身就应该携带EventTime如果以IngesingtTime为基准来定义时间窗口那将形成IngestingTimeWindow,以source的systemTime为准。如果以ProcessingTime基准来定义时间窗口那将形成ProcessingTimeWindow,以operator的systemTime为准。
在Flink的流式处理中,绝大部分的业务都会使用eventTime,一般只在eventTime无法使用时,才会被迫使用ProcessingTime或者IngestionTime。
如果要使用EventTime,那么需要引入EventTime的时间属性,引入方式如下所示:
val env = StreamExecutionEnvironment.getExecutionEnvironment
// 从调用时刻开始给env创建的每一个stream追加时间特征
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
2) Watermark
我们知道,流处理从事件产生,到流经 source,再到 operator,中间是有一个过程和时间的,虽然大部分情况下,流到 operator 的数据都是按照事件产生的时间顺序来的,但是也不排除由于网络、背压等原因,导致乱序的产生,所谓乱序,就是指 Flink 接收到的事件的先后顺序不是严格按照事件的 Event Time 顺序排列的,所以 Flink 最初设计的时候,就考虑到了网络延迟,网络乱序等问题,所以提出了一个抽象概念:水印(WaterMark);
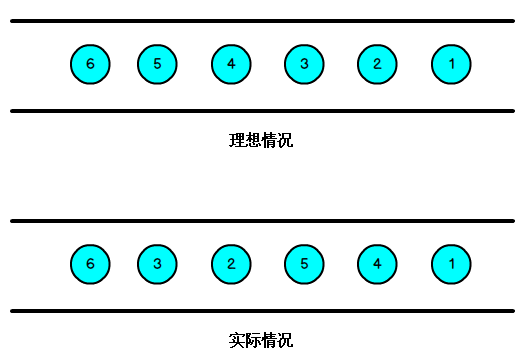
如上图所示,就出现一个问题,一旦出现乱序,如果只根据 EventTime 决定 Window 的运行,我们不能明确数据是否全部到位,但又不能无限期的等下去,此时必须要有个机制来保证一个特定的时间后,必须触发 Window 去进行计算了,这个特别的机制,就是 Watermark。
Watermark 是用于处理乱序事件的,而正确的处理乱序事件,通常用 Watermark 机制结合 Window 来实现。烹饪1-375
数据流中的 Watermark 用于表示 timestamp 小于 Watermark 的数据,都已经到达了,因此,Window 的执行也是由 Watermark 触发的。
Watermark 可以理解成一个延迟触发机制,我们可以设置 Watermark 的延时时长 t,每次系统会校验已经到达的数据中最大的 maxEventTime,然后认定 EventTime 小于 maxEventTime - t 的所有数据都已经到达,如果有窗口的停止时间等于 maxEventTime – t,那么这个窗口被触发执行。
有序流的Watermarker如下图所示:(Watermark设置为0)

有序数据的Watermark
乱序流的Watermarker如下图所示:(Watermark设置为2)

无序数据的Watermark
当 Flink 接收到每一条数据时,都会产生一条 Watermark,这条 Watermark 就等于当前所有到达数据中的 maxEventTime - 延迟时长,也就是说,Watermark 是由数据携带的,一旦数据携带的 Watermark 比当前未触发的窗口的停止时间要晚,那么就会触发相应窗口的执行。由于 Watermark 是由数据携带的,因此,如果运行过程中无法获取新的数据,那么没有被触发的窗口将永远都不被触发。
上图中,我们设置的允许最大延迟到达时间为2s,所以时间戳为7s的事件对应的Watermark是5s,时间戳为12s的事件的Watermark是10s,如果我们的窗口1是1s~5s,窗口2是6s~10s,那么时间戳为7s的事件到达时的Watermarker恰好触发窗口1,时间戳为12s的事件到达时的Watermark恰好触发窗口2。
3) Flink对于迟到数据的处理
waterMark和Window机制解决了流式数据的乱序问题,对于因为延迟而顺序有误的数据,可以根据eventTime进行业务处理,于延迟的数据Flink也有自己的解决办法,主要的办法是给定一个允许延迟的时间,在该时间范围内仍可以接受处理延迟数据。
设置允许延迟的时间是通过 allowedLateness(lateness: Time) 设置
保存延迟数据则是通过 sideOutputLateData(outputTag: OutputTag[T]) 保存
获取延迟数据是通过 DataStream.getSideOutput(tag: OutputTag[X]) 获取
具体的用法如下:
allowedLateness(lateness: Time)
def allowedLateness(lateness: Time): WindowedStream[T, K, W] = {
javaStream.allowedLateness(lateness)
this
}
该方法传入一个Time值,设置允许数据迟到的时间,这个时间和 WaterMark 中的时间概念不同。再来回顾一下:
WaterMark=数据的事件时间-允许乱序时间值
随着新数据的到来,waterMark的值会更新为最新数据事件时间-允许乱序时间值,但是如果这时候来了一条历史数据,waterMark值则不会更新。总的来说,waterMark是为了能接收到尽可能多的乱序数据。
那这里的Time值,主要是为了等待迟到的数据,在一定时间范围内,如果属于该窗口的数据到来,仍会进行计算,后面会对计算方式仔细说明
注意:该方法只针对于基于event-time的窗口,如果是基于processing-time,并且指定了非零的time值则会抛出异常。
sideOutputLateData(outputTag: OutputTag[T])
def sideOutputLateData(outputTag: OutputTag[T]): WindowedStream[T, K, W] = {
javaStream.sideOutputLateData(outputTag)
this
}
该方法是将迟来的数据保存至给定的outputTag参数,而OutputTag则是用来标记延迟数据的一个对象。
DataStream.getSideOutput(tag: OutputTag[X])
通过window等操作返回的DataStream调用该方法,传入标记延迟数据的对象来获取延迟的数据。
对延迟数据的理解
延迟数据是指:
在当前窗口【假设窗口范围为10-15】已经计算之后,又来了一个属于该窗口的数据【假设事件时间为13】,这时候仍会触发 Window 操作,这种数据就称为延迟数据。
那么问题来了,延迟时间怎么计算呢?
假设窗口范围为10-15,延迟时间为2s,则只要 WaterMark<15+2,并且属于该窗口,就能触发 Window 操作。而如果来了一条数据使得 WaterMark>=15+2,10-15这个窗口就不能再触发 Window 操作,即使新来的数据的 Event Time 属于这个窗口时间内 。
4) Flink 关联 Hive 分区表
Flink 1.12 支持了 Hive 最新的分区作为时态表的功能,可以通过 SQL 的方式直接关联 Hive 分区表的最新分区,并且会自动监听最新的 Hive 分区,当监控到新的分区后,会自动地做维表数据的全量替换。通过这种方式,用户无需编写 DataStream 程序即可完成 Kafka 流实时关联最新的 Hive 分区实现数据打宽。
具体用法:
在 Sql Client 中注册 HiveCatalog:
vim conf/sql-client-defaults.yaml
catalogs:
- name: hive_catalog
type: hive
hive-conf-dir: /disk0/soft/hive-conf/ #该目录需要包hive-site.xml文件
创建 Kafka 表
CREATE TABLE hive_catalog.flink_db.kfk_fact_bill_master_12 (

