SplitStream
支持将数据输出到:
本地文件(参考批处理)本地集合(参考批处理)HDFS(参考批处理)
除此之外,还支持:
sink到kafkasink到mysqlsink到redis
下面以sink到kafka为例:
val sinkTopic = "test"
//样例类
case class Student(id: Int, name: String, addr: String, sex: String)
val mapper: ObjectMapper = new ObjectMapper()
//将对象转换成字符串
def toJsonString(T: Object): String = {
mapper.registerModule(DefaultScalaModule)
mapper.writeValueAsString(T)
}
def main(args: Array[String]): Unit = {
//1.创建流执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
//2.准备数据
val dataStream: DataStream[Student] = env.fromElements(
Student(8, "xiaoming", "beijing biejing", "female")
)
//将student转换成字符串
val studentStream: DataStream[String] = dataStream.map(student =>
toJsonString(student) // 这里需要显示SerializerFeature中的某一个,否则会报同时匹配两个方法的错误
)
//studentStream.print()
val prop = new Properties()
prop.setProperty("bootstrap.servers", "node01:9092")
val myProducer = new FlinkKafkaProducer011[String](sinkTopic, new KeyedSerializationSchemaWrapper[String](new SimpleStringSchema()), prop)
studentStream.addSink(myProducer)
studentStream.print()
env.execute("Flink add sink")
}
五、流处理中的Time与Window
Flink 是流式的、实时的 计算引擎。
上面一句话就有两个概念,一个是流式,一个是实时。
流式:就是数据源源不断的流进来,也就是数据没有边界,但是我们计算的时候必须在一个有边界的范围内进行,所以这里面就有一个问题,边界怎么确定?无非就两种方式,根据时间段或者数据量进行确定,根据时间段就是每隔多长时间就划分一个边界,根据数据量就是每来多少条数据划分一个边界,Flink 中就是这么划分边界的,本文会详细讲解。烹饪1-375
实时:就是数据发送过来之后立马就进行相关的计算,然后将结果输出。这里的计算有两种:
一种是只有边界内的数据进行计算,这种好理解,比如统计每个用户最近五分钟内浏览的新闻数量,就可以取最近五分钟内的所有数据,然后根据每个用户分组,统计新闻的总数。
另一种是边界内数据与外部数据进行关联计算,比如:统计最近五分钟内浏览新闻的用户都是来自哪些地区,这种就需要将五分钟内浏览新闻的用户信息与 hive 中的地区维表进行关联,然后在进行相关计算。
本节所讲的 Flink 内容就是围绕以上概念进行详细剖析的!
1. Time
在Flink中,如果以时间段划分边界的话,那么时间就是一个极其重要的字段。
Flink中的时间有三种类型,如下图所示:
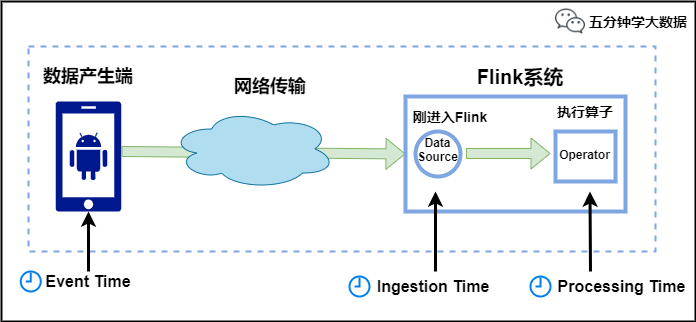
Event Time:是事件创建的时间。它通常由事件中的时间戳描述,例如采集的日志数据中,每一条日志都会记录自己的生成时间,Flink通过时间戳分配器访问事件时间戳。
Ingestion Time:是数据进入Flink的时间。
Processing Time:是每一个执行基于时间操作的算子的本地系统时间,与机器相关,默认的时间属性就是Processing Time。
例如,一条日志进入Flink的时间为2021-01-22 10:00:00.123,到达Window的系统时间为2021-01-22 10:00:01.234,日志的内容如下:
2021-01-06 18:37:15.624 INFO Fail over to rm2
对于业务来说,要统计1min内的故障日志个数,哪个时间是最有意义的?—— eventTime,因为我们要根据日志的生成时间进行统计。
2. Window
Window,即窗口,我们前面一直提到的边界就是这里的Window(窗口)。
官方解释:流式计算是一种被设计用于处理无限数据集的数据处理引擎,而无限数据集是指一种不断增长的本质上无限的数据集,而window是一种切割无限数据为有限块进行处理的手段。
所以Window是无限数据流处理的核心,Window将一个无限的stream拆分成有限大小的”buckets”桶,我们可以在这些桶上做计算操作。
Window类型
本文刚开始提到,划分窗口就两种方式:
根据时间进行截取(time-driven-window),比如每1分钟统计一次或每10分钟统计一次。根据数据进行截取(data-driven-window),比如每5个数据统计一次或每50个数据统计一次。
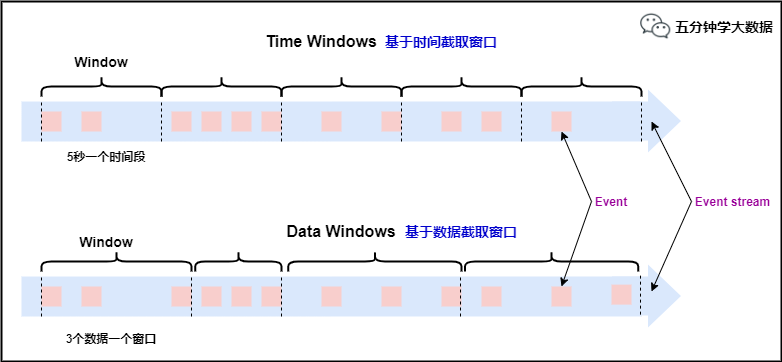
窗口类型
对于TimeWindow(根据时间划分窗口), 可以根据窗口实现原理的不同分成三类:滚动窗口(Tumbling Window)、滑动窗口(Sliding Window)和会话窗口(Session Window)。
滚动窗口(Tumbling Windows)
将数据依据固定的窗口长度对数据进行切片。
特点:时间对齐,窗口长度固定,没有重叠。
滚动窗口分配器将每个元素分配到一个指定窗口大小的窗口中,滚动窗口有一个固定的大小,并且不会出现重叠。
例如:如果你指定了一个5分钟大小的滚动窗口,窗口的创建如下图所示:

滚动窗口
适用场景:适合做BI统计等(做每个时间段的聚合计算)。
滑动窗口(Sliding Windows)
滑动窗口是固定窗口的更广义的一种形式,滑动窗口由固定的窗口长度和滑动间隔组成。
特点:时间对齐,窗口长度固定,有重叠。
滑动窗口分配器将元素分配到固定长度的窗口中,与滚动窗口类似,窗口的大小由窗口大小参数来配置,另一个窗口滑动参数控制滑动窗口开始的频率。因此,滑动窗口如果滑动参数小于窗口大小的话,窗口是可以重叠的,在这种情况下元素会被分配到多个窗口中。
例如,你有10分钟的窗口和5分钟的滑动,那么每个窗口中5分钟的窗口里包含着上个10分钟产生的数据,如下图所示:
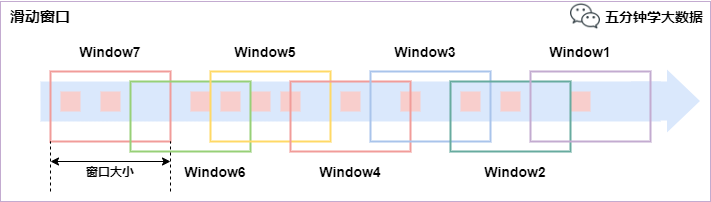
滑动窗口
适用场景:对最近一个时间段内的统计(求某接口最近5min的失败率来决定是否要报警)。
会话窗口(Session Windows)
由一系列事件组合一个指定时间长度的timeout间隙组成,类似于web应用的session,也就是一段时间没有接收到新数据就会生成新的窗口。
特点:时间无对齐。
session窗口分配器通过session活动来对元素进行分组,session窗口跟滚动窗口和滑动窗口相比,不会有重叠和固定的开始时间和结束时间的情况,相反,当它在一个固定的时间周期内不再收到元素,即非活动间隔产生,那个这个窗口就会关闭。一个session窗口通过一个session间隔来配置,这个session间隔定义了非活跃周期的长度,当这个非活跃周期产生,那么当前的session将关闭并且后续的元素将被分配到新的session窗口中去。
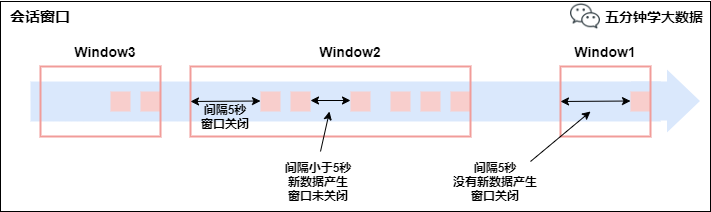
会话窗口3. Window API1) TimeWindow
TimeWindow是将指定时间范围内的所有数据组成一个window,一次对一个window里面的所有数据进行计算(就是本文开头说的对一个边界内的数据进行计算)。
我们以 红绿灯路口通过的汽车数量 为例子:
红绿灯路口会有汽车通过,一共会有多少汽车通过,无法计算。因为车流源源不断,计算没有边界。
所以我们统计每15秒钟通过红路灯的汽车数量,如第一个15秒为2辆,第二个15秒为3辆,第三个15秒为1辆 ...
tumbling-time-window (无重叠数据)
我们使用 Linux 中的 nc 命令模拟数据的发送方
1.开启发送端口,端口号为9999
nc -lk 9999
2.发送内容(key 代表不同的路口,value 代表每次通过的车辆)
一次发送一行,发送的时间间隔代表汽车经过的时间间隔
9,3
9,2
9,7
4,9
2,6
1,5
2,3
5,7
5,4
Flink 进行采集数据并计算:
object Window {
def main(args: Array[String]): Unit = {
//TODO time-window
//1.创建运行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
//2.定义数据流来源
val text = env.socketTextStream("localhost", 9999)
//3.转换数据格式,text->CarWc
case class CarWc(sensorId: Int, carCnt: Int)
val ds1: DataStream[CarWc] = text.map {
line => {
val tokens = line.split(",")
CarWc(tokens(0).trim.toInt, tokens(1).trim.toInt)
}
}
//4.执行统计操作,每个sensorId一个tumbling窗口,窗口的大小为5秒
//也就是说,每5秒钟统计一次,在这过去的5秒钟内,各个路口通过红绿灯汽车的数量。
val ds2: DataStream[CarWc] = ds1
.keyBy("sensorId")
.timeWindow(Time.seconds(5))
.sum("carCnt")
//5.显示统计结果
ds2.print()
//6.触发流计算
env.execute(this.getClass.getName)
}
}
我们发送的数据并没有指定时间字段,所以Flink使用的是默认的 Processing Time,也就是Flink系统处理数据时的时间。烹饪1-375
sliding-time-window (有重叠数据)//1.创建运行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
//2.定义数据流来源
val text = env.socketTextStream("localhost", 9999)
//3.转换数据格式,text->CarWc
case class CarWc(sensorId: Int, carCnt: Int)
val ds1: DataStream[CarWc] = text.map {
line => {
val tokens = line.split(",")
CarWc(tokens(0).trim.toInt, tokens(1).trim.toInt)
}
}
//4.执行统计操作,每个sensorId一个sliding窗口,窗口时间10秒,滑动时间5秒
//也就是说,每5秒钟统计一次,在这过去的10秒钟内,各个路口通过红绿灯汽车的数量。
val ds2: DataStream[CarWc] = ds1
.keyBy("sensorId")
.timeWindow(Time.seconds(10), Time.seconds(5))
.sum("carCnt")
//5.显示统计结果
ds2.print()
//6.触发流计算
env.execute(this.getClass.getName)
2) CountWindow
CountWindow根据窗口中相同key元素的数量来触发执行,执行时只计算元素数量达到窗口大小的key对应的结果。
注意:CountWindow的window_size指的是相同Key的元素的个数,不是输入的所有元素的总数。
tumbling-count-window (无重叠数据)//1.创建运行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
//2.定义数据流来源
val text = env.socketTextStream("localhost", 9999)
//3.转换数据格式,text->CarWc
case class CarWc(sensorId: Int, carCnt: Int)
val ds1: DataStream[CarWc] = text.map {
(f) => {
val tokens = f.split(",")
CarWc(tokens(0).trim.toInt, tokens(1).trim.toInt)
}
}
//4.执行统计操作,每个sensorId一个tumbling窗口,窗口的大小为5
//按照key进行收集,对应的key出现的次数达到5次作为一个结果
val ds2: DataStream[CarWc] = ds1
.keyBy("sensorId")
.countWindow(5)
.sum("carCnt")
//5.显示统计结果
ds2.print()
//6.触发流计算
env.execute(this.getClass.getName)
sliding-count-window (有重叠数据)
同样也是窗口长度和滑动窗口的操作:窗口长度是5,滑动长度是3
//1.创建运行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
//2.定义数据流来源
val text = env.socketTextStream("localhost", 9999)
//3.转换数据格式,text->CarWc
case class CarWc(sensorId: Int, carCnt: Int)
val ds1: DataStream[CarWc] = text.map {
(f) => {
val tokens = f.split(",")
CarWc(tokens(0).trim.toInt, tokens(1).trim.toInt)
}
}
//4.执行统计操作,每个sensorId一个sliding窗口,窗口大小3条数据,窗口滑动为3条数据
//也就是说,每个路口分别统计,收到关于它的3条消息时统计在最近5条消息中,各自路口通过的汽车数量
val ds2: DataStream[CarWc] = ds1
.keyBy("sensorId")
.countWindow(5, 3)
.sum("carCnt")
//5.显示统计结果
ds2.print()
//6.触发流计算
env.execute(this.getClass.getName)
Window 总结
flink支持两种划分窗口的方式(time和count)
如果根据时间划分窗口,那么它就是一个time-window
如果根据数据划分窗口,那么它就是一个count-window
flink支持窗口的两个重要属性(size和interval)
如果size=interval,那么就会形成tumbling-window(无重叠数据)
如果size>interval,那么就会形成sliding-window(有重叠数据)

