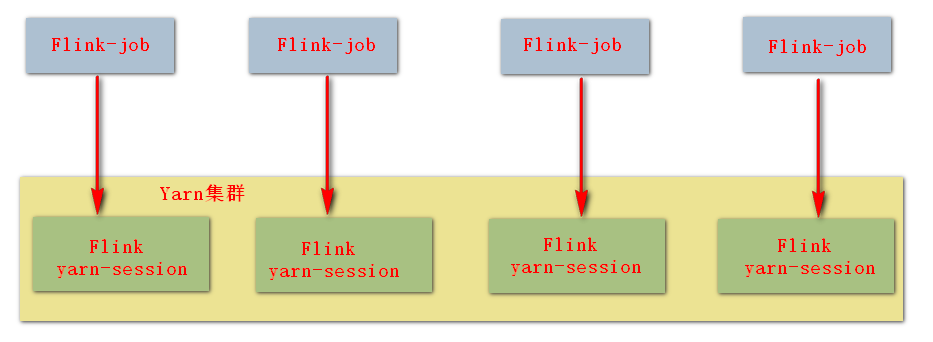
直接提交任务给 YARN;
大作业,适合使用这种方式;
会自动关闭 session。
使用 flink 直接提交任务:
bin/flink run -m yarn-cluster -yn 2 -yjm 800 -ytm 800 /export/servers/flink-1.6.0/examples/batch/WordCount.jar
-yn 表示 TaskManager 的个数
注意:
在创建集群的时候,集群的配置参数就写好了,但是往往因为业务需要,要更改一些配置参数,这个时候可以不必因为一个实例的提交而修改 conf/flink-conf.yaml;
可以通过:-D
-Dfs.overwrite-files=true -Dtaskmanager.network.numberOfBuffers=16368
如果使用的是 flink on yarn 方式,想切换回 standalone 模式的话,需要删除:/tmp/.yarn-properties-root,因为默认查找当前 yarn 集群中已有的 yarn-session 信息中的 jobmanager。三、Flink 运行架构1. Flink 程序结构
Flink 程序的基本构建块是流和转换(请注意,Flink 的 DataSet API 中使用的 DataSet 也是内部流 )。从概念上讲,流是(可能永无止境的)数据记录流,而转换是将一个或多个流作为一个或多个流的操作。输入,并产生一个或多个输出流。
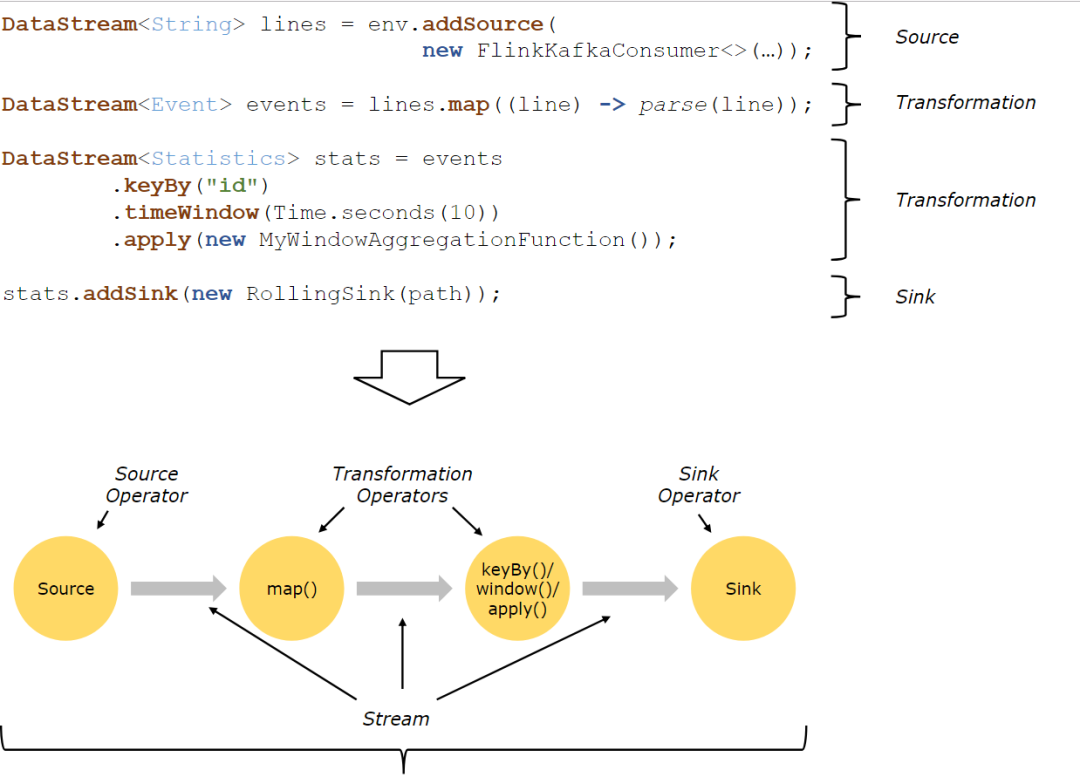
Flink 赢咖4平台结构就是如上图所示:
Source: 数据源,Flink 在流处理和批处理上的 source 大概有 4 类:基于本地集合的 source、基于文件的 source、基于网络套接字的 source、自定义的 source。自定义的 source 常见的有 Apache kafka、RabbitMQ 等,当然你也可以定义自己的 source。
Transformation:数据转换的各种操作,有 Map / FlatMap / Filter / KeyBy / Reduce / Fold / Aggregations / Window / WindowAll / Union / Window join / Split / Select等,操作很多,可以将数据转换计算成你想要的数据。
Sink:接收器,Flink 将转换计算后的数据发送的地点 ,你可能需要存储下来,Flink 常见的 Sink 大概有如下几类:写入文件、打印出来、写入 socket 、自定义的 sink 。自定义的 sink 常见的有 Apache kafka、RabbitMQ、MySQL、ElasticSearch、Apache Cassandra、Hadoop FileSystem 等,同理你也可以定义自己的 sink。
2. Flink 并行数据流
Flink 程序在执行的时候,会被映射成一个 Streaming Dataflow,一个 Streaming Dataflow 是由一组 Stream 和 Transformation Operator 组成的。在启动时从一个或多个 Source Operator 开始,结束于一个或多个 Sink Operator。烹饪1-375
Flink 程序本质上是并行的和分布式的,在执行过程中,一个流(stream)包含一个或多个流分区,而每一个 operator 包含一个或多个 operator 子任务。操作子任务间彼此独立,在不同的线程中执行,甚至是在不同的机器或不同的容器上。operator 子任务的数量是这一特定 operator 的并行度。相同程序中的不同 operator 有不同级别的并行度。
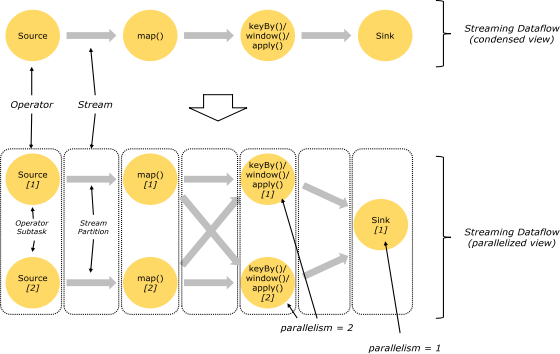
一个 Stream 可以被分成多个 Stream 的分区,也就是 Stream Partition。一个 Operator 也可以被分为多个 Operator Subtask。如上图中,Source 被分成 Source1 和 Source2,它们分别为 Source 的 Operator Subtask。每一个 Operator Subtask 都是在不同的线程当中独立执行的。一个 Operator 的并行度,就等于 Operator Subtask 的个数。上图 Source 的并行度为 2。而一个 Stream 的并行度就等于它生成的 Operator 的并行度。
数据在两个 operator 之间传递的时候有两种模式:
One to One 模式:两个 operator 用此模式传递的时候,会保持数据的分区数和数据的排序;如上图中的 Source1 到 Map1,它就保留的 Source 的分区特性,以及分区元素处理的有序性。
Redistributing (重新分配)模式:这种模式会改变数据的分区数;每个一个 operator subtask 会根据选择 transformation 把数据发送到不同的目标 subtasks,比如 keyBy()会通过 hashcode 重新分区,broadcast()和 rebalance()方法会随机重新分区;
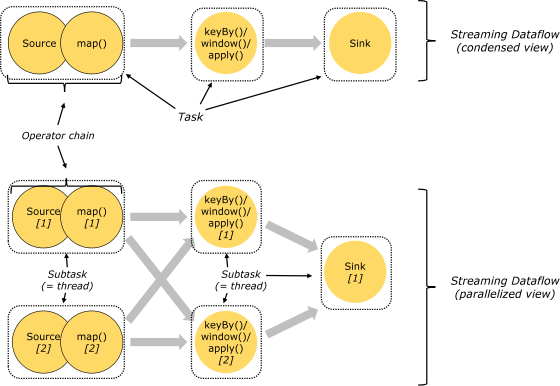
3. Task 和 Operator chain
Flink的所有操作都称之为Operator,客户端在提交任务的时候会对Operator进行优化操作,能进行合并的Operator会被合并为一个Operator,合并后的Operator称为Operator chain,实际上就是一个执行链,每个执行链会在TaskManager上一个独立的线程中执行。
4. 任务调度与执行
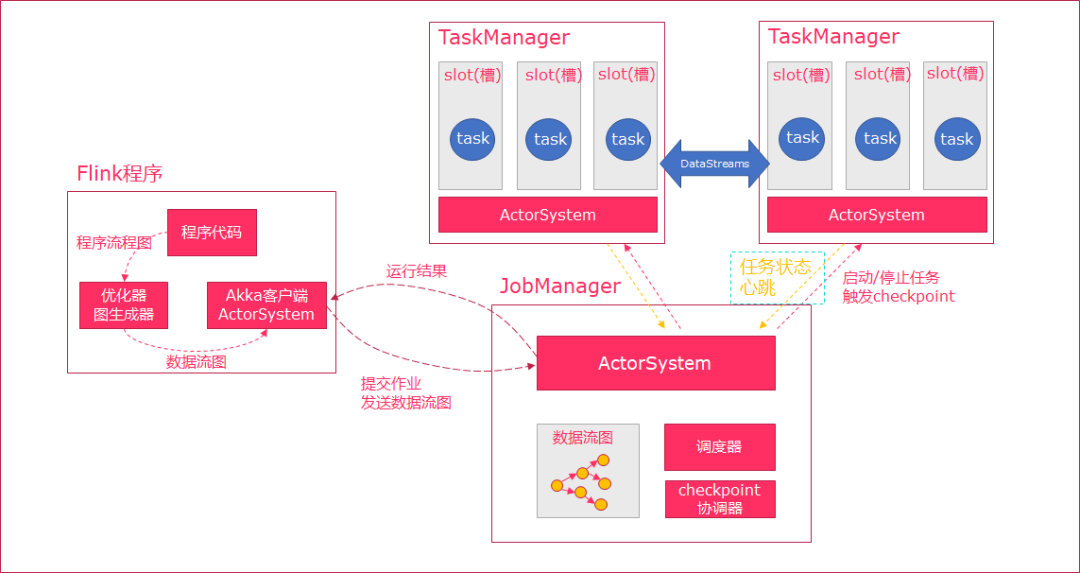
当Flink执行executor会自动根据程序代码生成DAG数据流图;
ActorSystem创建Actor将数据流图发送给JobManager中的Actor;
JobManager会不断接收TaskManager的心跳消息,从而可以获取到有效的TaskManager;
JobManager通过调度器在TaskManager中调度执行Task(在Flink中,最小的调度单元就是task,对应就是一个线程);
在程序运行过程中,task与task之间是可以进行数据传输的。
Job Client:
主要职责是提交任务, 提交后可以结束进程, 也可以等待结果返回;Job Client 不是 Flink 程序执行的内部部分,但它是任务执行的起点;Job Client 负责接受用户的程序代码,然后创建数据流,将数据流提交给 Job Manager 以便进一步执行。执行完成后,Job Client 将结果返回给用户。
JobManager:
主要职责是调度工作并协调任务做检查点;集群中至少要有一个 master,master 负责调度 task,协调checkpoints 和容错;高可用设置的话可以有多个 master,但要保证一个是 leader, 其他是standby;Job Manager 包含 Actor System、Scheduler、CheckPoint三个重要的组件;JobManager从客户端接收到任务以后, 首先生成优化过的执行计划, 再调度到TaskManager中执行。烹饪1-375
TaskManager:
主要职责是从JobManager处接收任务, 并部署和启动任务, 接收上游的数据并处理;Task Manager 是在 JVM 中的一个或多个线程中执行任务的工作节点;TaskManager在创建之初就设置好了Slot, 每个Slot可以执行一个任务。5. 任务槽和槽共享
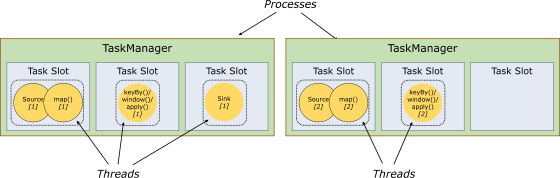
每个TaskManager是一个JVM的进程, 可以在不同的线程中执行一个或多个子任务。为了控制一个worker能接收多少个task。worker通过task slot来进行控制(一个worker至少有一个task slot)。
1) 任务槽
每个task slot表示TaskManager拥有资源的一个固定大小的子集。
flink将进程的内存进行了划分到多个slot中。
图中有2个TaskManager,每个TaskManager有3个slot的,每个slot占有1/3的内存。
内存被划分到不同的slot之后可以获得如下好处:
TaskManager最多能同时并发执行的任务是可以控制的,那就是3个,因为不能超过slot的数量。
slot有独占的内存空间,这样在一个TaskManager中可以运行多个不同的作业,作业之间不受影响。
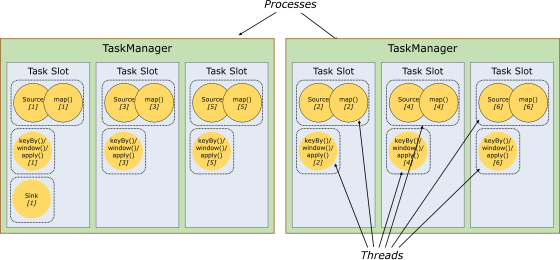
2) 槽共享
默认情况下,Flink允许子任务共享插槽,即使它们是不同任务的子任务,只要它们来自同一个作业。结果是一个槽可以保存作业的整个管道。允许插槽共享有两个主要好处:
只需计算Job中最高并行度(parallelism)的task slot,只要这个满足,其他的job也都能满足。
资源分配更加公平,如果有比较空闲的slot可以将更多的任务分配给它。图中若没有任务槽共享,负载不高的Source/Map等subtask将会占据许多资源,而负载较高的窗口subtask则会缺乏资源。
有了任务槽共享,可以将基本并行度(base parallelism)从2提升到6.提高了分槽资源的利用率。同时它还可以保障TaskManager给subtask的分配的slot方案更加公平。
四、Flink 算子大全
Flink和Spark类似,也是一种一站式处理的框架;既可以进行批处理(DataSet),也可以进行实时处理(DataStream)。
所以下面将Flink的算子分为两大类:一类是DataSet,一类是DataStream。
DataSet 批处理算子一、Source算子1. fromCollection
fromCollection:从本地集合读取数据
例:
val env = ExecutionEnvironment.getExecutionEnvironment
val textDataSet: DataSet[String] = env.fromCollection(
List("1,张三", "2,李四", "3,王五", "4,赵六")
)
2. readTextFile
readTextFile:从文件中读取
val textDataSet: DataSet[String] = env.readTextFile("/data/a.txt")
3. readTextFile:遍历目录
readTextFile可以对一个文件目录内的所有文件,包括所有子目录中的所有文件的遍历访问方式
val parameters = new Configuration
// recursive.file.enumeration 开启递归
parameters.setBoolean("recursive.file.enumeration", true)
val file = env.readTextFile("/data").withParameters(parameters)
4. readTextFile:读取压缩文件
对于以下压缩类型,不需要指定任何额外的inputformat方法,flink可以自动识别并且解压。但是,压缩文件可能不会并行读取,可能是顺序读取的,这样可能会影响作业的可伸缩性。
压缩方法文件扩展名是否可并行读取DEFLATE.deflatenoGZip.gz .gzipnoBzip2.bz2noXZ.xznoval file = env.readTextFile("/data/file.gz")
二、Transform转换算子
因为Transform算子基于Source算子操作,所以首先构建Flink执行环境及Source算子,后续Transform算子操作基于此:
val env = ExecutionEnvironment.getExecutionEnvironment
val textDataSet: DataSet[String] = env.fromCollection(
List("张三,1", "李四,2", "王五,3", "张三,4")
)
1. map
将DataSet中的每一个元素转换为另外一个元素
// 使用map将List转换为一个Scala的样例类
case class User(name: String, id: String)
val userDataSet: DataSet[User] = textDataSet.map {
text =>
val fieldArr = text.split(",")
User(fieldArr(0), fieldArr(1))
}
userDataSet.print()
2. flatMap
将DataSet中的每一个元素转换为0...n个元素。
// 使用flatMap操作,将集合中的数据:
// 根据第一个元素,进行分组
// 根据第二个元素,进行聚合求值
val result = textDataSet.flatMap(line => line)
.groupBy(0) // 根据第一个元素,进行分组
.sum(1) // 根据第二个元素,进行聚合求值
result.print()
3. mapPartition
将一个分区中的元素转换为另一个元素
// 使用mapPartition操作,将List转换为一个scala的样例类
case class User(name: String, id: String)
val result: DataSet[User] = textDataSet.mapPartition(line => {
line.map(index => User(index._1, index._2))
})
result.print()
4. filter
过滤出来一些符合条件的元素,返回boolean值为true的元素
val source: DataSet[String] = env.fromElements("java", "scala", "java")
val filter:DataSet[String] = source.filter(line => line.contains("java"))//过滤出带java的数据
filter.print()
5. reduce
可以对一个dataset或者一个group来进行聚合计算,最终聚合成一个元素
// 使用 fromElements 构建数据源
val source = env.fromElements(("java", 1), ("scala", 1), ("java", 1))
// 使用map转换成DataSet元组
val mapData: DataSet[(String, Int)] = source.map(line => line)
// 根据首个元素分组
val groupData = mapData.groupBy(_._1)
// 使用reduce聚合
val reduceData = groupData.reduce((x, y) => (x._1, x._2 + y._2))
// 打印测试
reduceData.print()
6. reduceGroup
将一个dataset或者一个group聚合成一个或多个元素。
reduceGroup是reduce的一种优化方案;
它会先分组reduce,然后在做整体的reduce;这样做的好处就是可以减少网络IO
// 使用 fromElements 构建数据源
val source: DataSet[(String, Int)] = env.fromElements(("java", 1), ("scala", 1), ("java", 1))
// 根据首个元素分组
val groupData = source.groupBy(_._1)
// 使用reduceGroup聚合
val result: DataSet[(String, Int)] = groupData.reduceGroup {
(in: Iterator[(String, Int)], out: Collector[(String, Int)]) =>
val tuple = in.reduce((x, y) => (x._1, x._2 + y._2))
out.collect(tuple)
}
// 打印测试
result.print()
7. minBy和maxBy
选择具有最小值或最大值的元素
// 使用minBy操作,求List中每个人的最小值
// List("张三,1", "李四,2", "王五,3", "张三,4")
case class User(name: String, id: String)
// 将List转换为一个scala的样例类
val text: DataSet[User] = textDataSet.mapPartition(line => {
line.map(index => User(index._1, index._2))
})
val result = text
.groupBy(0) // 按照姓名分组
.minBy(1) // 每个人的最小值

