以上介绍的级联形状回归方法每一个回归函数fi都是浅层模型(线性回归模型、Random Fern等)。深度网络模型,比如卷积神经网络(CNN)、深度自编码器(DAE)和受限玻尔兹曼机(RBM)在计算机视觉的诸多问题,如场景分类,目标跟踪,图像分割等任务中有着广泛的应用,当然也包括特征定位问题。具体的方法可以分为两大类:使用深度模型建模人脸形状和表观的变化和基于深度网络学习从人脸表观到形状的非线性映射函数。
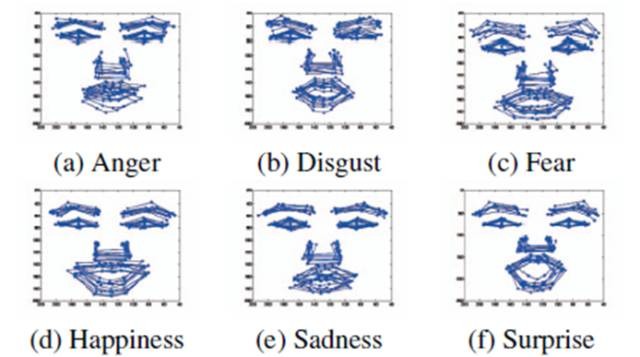
主动形状模型ASM和主动表观模型AAM使用主成分分析(PCA)来建模人脸形状的变化。由于姿态表情等因素的影响,线性PCA模型很难完美地刻画不同表情和姿态下的人脸形状变化。来自伦斯勒理工学院JiQiang教授的课题组在CVPR2013提出使用深度置信网络(DBN)来刻画不同表情下人脸形状的复杂非线性变化。此外,为了处理不同姿态的特征点定位问题,进一步使用3向RBM网络建模从正面到非正面的人脸形状变化。最终该方法在表情数据库CK+上取得比线性模型AAM更好的定位结果。该方法在同时具备多姿态多表情的数据库ISL上也取得较好的定位效果,但对同时出现极端姿态和夸张表情变化的情况还不够理想。
下图是深度置信网络(DBN):建模不同表情下的人脸形状变化的示意图。
香港中文大学唐晓鸥教授的课题组在CVPR 2013上提出3级卷积神经网络DCNN来实现面部特征点定位的方法。该方法也可以统一在级联形状回归模型的大框架下,和CPR、RCPR、SDM、LBF等方法不一样的是,DCNN使用深度模型-卷积神经网络,来实现fi。第一级f1使用人脸图像的三块不同区域(整张人脸,眼睛和鼻子区域,鼻子和嘴唇区域)作为输入,分别训练3个卷积神经网络来预测特征点的位置,网络结构包含4个卷积层,3个Pooling层和2个全连接层,并融合三个网络的预测来得到更加稳定的定位结果。后面两级f2, f3在每个特征点附近抽取特征,针对每个特征点单独训练一个卷积神经网络(2个卷积层,2个Pooling层和1个全连接层)来修正定位的结果。该方法在LFPW数据集上取得当时最好的定位结果。

借此机会也介绍本人发表在欧洲视觉会议ECCV2014的一个工作:即提出一种由粗到精的自编码器网络(CFAN)来描述从人脸表观到人脸形状的复杂非线性映射过程。该方法级联了多个栈式自编码器网络fi,每一个fi刻画从人脸表观到人脸形状的部分非线性映射。具体来说,输入一个低分辨率的人脸图像I,第一层自编码器网络f1可以快速地估计大致的人脸形状,记作基于全局特征的栈式自编码网络。网络f1包含三个隐层,隐层节点数分别为1600,900,400。然后提高人脸图像的分辨率,并根据f1得到的初始人脸形状θ1,抽取联合局部特征,输入到下一层自编码器网络f2来同时优化、调整所有特征点的位置,记作基于局部特征的栈式自编码网络。该方法级联了3个局部栈式自编码网络{f2 , f3, f4}直到在训练集上收敛。每一个局部栈式自编码网络包含三个隐层,隐层节点数分别为1296,784,400。得益于深度模型强大的非线性刻画能力,该方法在XM2VTS,LFPW,HELEN数据集上取得比DRMF、SDM更好的结果。此外,CFAN可以实时地完成人脸面部特征点定位(在I7的台式机上达到23毫秒/张),比DCNN(120毫秒/张)具有更快的处理速度。 下图是CFAN:基于由粗到精自编码器网络的实时面部特征点定位方法的示意图。

以上基于级联形状回归和深度学习的方法对于大姿态(左右旋转-60°~+60°)、各种表情变化都能得到较好的定位结果,处理速度快,具备很好的产品应用前景。针对纯侧面(±90°)、部分遮挡以及人脸检测与特征定位联合估计等问题的解决仍是目前的研究热点。

