由于步长(stride)不为一的卷积层和池化层产生的特征图(feature map)大小会有一些向下取整操作, 导致最后的feature map大小与原图不是严格的倍数关系。例如对如下的一个pooling层,
- {
- name:"pool1"
- type: "Pooling"
- bottom: "conv1_2"
- top: "pool1"
- pooling_param {
- kernel_size: 2
- stride: 2
- }
- }
前层输入大小为 11x11 的特征图, 其输出的特征图大小为(11 - 2) / 2 + 1 = 5, 并不是输入大小11的整数倍。上采样不能完全保证最后的perpixel prediction 结果与原图大小严格相同, 因此在上采样(Deconvlution)之后会有一个crop层, 将上采样的结果进行裁剪, 使之大小与输入图像严格相等。
下图是Longjon用于语义分割所采用的全卷积网络(FCN)的结构示意图, 在Alexnet基础上, 最后的channel=4096的feature map经过一个1x1的卷积层, 变为channel=21的feature map, 然后经过上采样和crop, 变为与输入图像同样大小的channel=21的feature map, 也就是图中的pixel-wise prediction。 在Longjon的试验中一共有20个语义类别, 加上背景类别每个像素应该有21个softmax预测类, 因此pixel-wise prediction中channel=21。
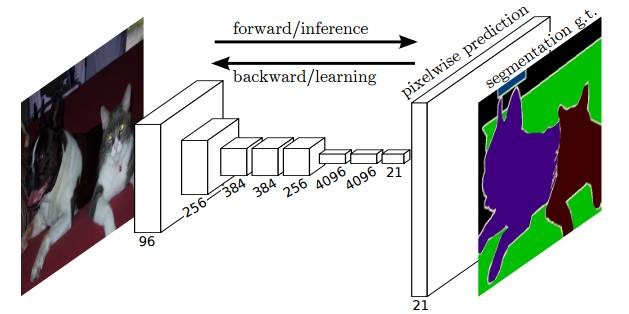
FCN能够端到端(end to end)得到每个像素的预测结果, 目前也涌现了一大批基于FCN的算法, 例如边缘检测(edge detection), 视觉跟踪(visual tracking)等。同时FCN也可以省去传统识别中复杂的逐patch计算过程, 我们曾经在一个燃气表数字识别的项目中使用FCN直接得到如下图所示燃气表图片中的数字识别结果, 如果使用经典的用于数字识别的LeNet-5网络, 就需要对下图进行字符检测然后取patch归一化后进行分类。赢咖4注册
在训练阶段, 我们标定燃气表数字中心一块区域的像素点为该类数字的正样本, 如下图所示, 不同数字的中心区域的像素被标定为不同的类别, 十种数字加上背景一共十一类, 不同颜色表示不同类别的标注, 其他的都是背景类。最后对每个像素计算softmax loss。

测试阶段通过全卷积网络得到输入燃气表图像每一个像素的分类结果, 接着进行非极大值抑制, 形态学变换等后续操作, 可直接得到上图的识别结果"001832", 整个系统十分高效。我们开源了基于Caffe的实现,代码链接 http://github.com/SHUCV/digit

