前言
在计算机发展和互联网渗透下,世界上的数据规模呈爆发式增长,普通人越来越容易获取这些数据,赢咖4也实现了从早期的人工特征工程到现在能够自动从海量数据中学习的华丽转变,计算机视觉、语音识别和自然语言处理等应用也取得众多突破。这其中最流行的一类技术称为深度学习,曾在工业界引起了不小的轰动。
1. 卷积神经网络
卷积神经网络缩写为CNN,最早受神经科学研究的启发。经过长达20多年的演变,CNN在计算机视觉、AI领域越来越突出,著名的在围棋对抗中以 4 : 1 大比分优势战胜李世石的 AlphaGo 就采用了 CNN + 蒙特卡洛搜索树算法。
一个典型CNN由两部分组成:特征提取器 + 分类器。特征提取器用于过滤输入图像,产生表示图像不同特征的特征图。这些特征可能包括拐角,线,圆弧等,对位置和形变不敏感。特征提取器的输出是包含这些特征的低维向量。该向量送入分类器(通常基于传统的人工神经网络),得到输入属于某个类别的可能性。下图展示了一个真实 CNN 模型架构【6】。
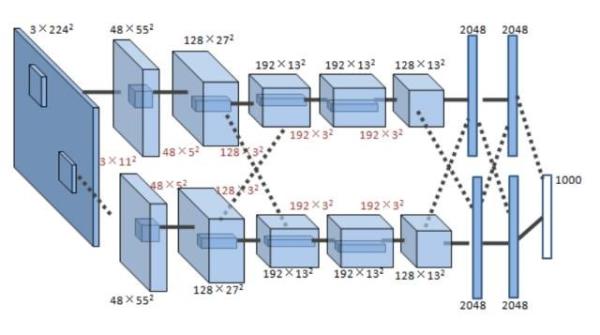
该CNN包括8层,前5层为卷积层,第6~8层为全连接层。输入层为3通道224 x 224输入图像(由原始三通道256 x 256 RGB图像缩放得到),输出1000维向量表示该图像属于1000个类别的概率密度分布。
一个典型CNN包括多个计算层,其中特征提取器包括若干个卷积层和(可选的)下采样层。
卷积层以N个特征图作为输入,每个输入特征图被一个K * K的核卷积,产生一个输出特征图的一个像素。滑动窗的间隔为S,一般小于K。总共产生M个输出特征图。卷积层的 C 代码如下:

需要说明,上述6层循环实现只是为了便于理解,不是最优的算法。从该实现也可以得出卷积层一次前向传播的计算量为(R x C x M x N x K x K)次乘加。
论文【7】证明卷积层会占据超过90%的总计算时间,所以本文我们关注卷积层硬件加速。
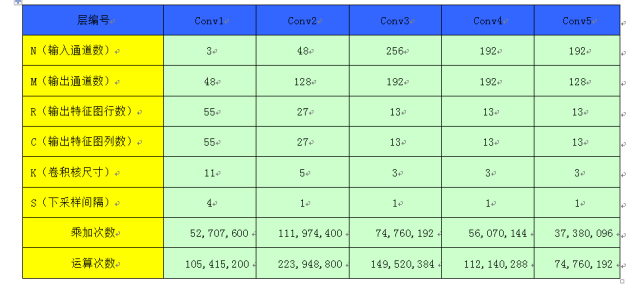
下表记录了 AlexNet 模型的各个卷积层参数配置和计算量情况