三. 基于回归方法的深度学习目标检测算法
Faster R-CNN的方法目前是主流的目标检测方法,但是速度上并不能满足实时的要求。YOLO一类的方法慢慢显现出其重要性,这类方法使用了回归的思想,既给定输入图像,直接在图像的多个位置上回归出这个位置的目标边框以及目标类别。
1.YOLO (CVPR2016, oral)
(You Only Look Once: Unified, Real-Time Object Detection)
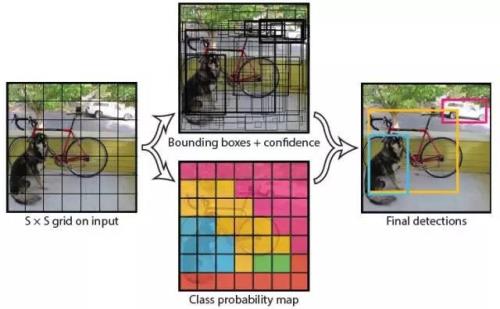
我们直接看上面YOLO的目标检测的流程图:
(1) 给个一个输入图像,首先将图像划分成7*7的网格
(2) 对于每个网格,我们都预测2个边框(包括每个边框是目标的置信度以及每个边框区域在多个类别上的概率)
(3) 根据上一步可以预测出7*7*2个目标窗口,然后根据阈值去除可能性比较低的目标窗口,最后NMS去除冗余窗口即可。
可以看到整个过程非常简单,不需要中间的region proposal在找目标,直接回归便完成了位置和类别的判定。

那么如何才能做到直接在不同位置的网格上回归出目标的位置和类别信息呢?上面是YOLO的网络结构图,前边的网络结构跟GoogLeNet的模型比较类似,主要的是最后两层的结构,卷积层之后接了一个4096维的全连接层,然后后边又全连接到一个7*7*30维的张量上。实际上这7*7就是划分的网格数,现在要在每个网格上预测目标两个可能的位置以及这个位置的目标置信度和类别,也就是每个网格预测两个目标,每个目标的信息有4维坐标信息(中心点坐标+长宽),1个是目标的置信度,还有类别数20(VOC上20个类别),总共就是(4+1)*2+20 = 30维的向量。这样可以利用前边4096维的全图特征直接在每个网格上回归出目标检测需要的信息(边框信息加类别)。
小结:YOLO将目标检测任务转换成一个回归问题,大大加快了检测的速度,使得YOLO可以每秒处理45张图像。而且由于每个网络预测目标窗口时使用的是全图信息,使得false positive比例大幅降低(充分的上下文信息)。但是YOLO也存在问题:没有了region proposal机制,只使用7*7的网格回归会使得目标不能非常精准的定位,这也导致了YOLO的检测精度并不是很高。
2.SSD
(SSD: Single Shot MultiBox Detector)
上面分析了YOLO存在的问题,使用整图特征在7*7的粗糙网格内回归对目标的定位并不是很精准。那是不是可以结合region proposal的思想实现精准一些的定位?SSD结合YOLO的回归思想以及Faster R-CNN的anchor机制做到了这点。

上图是SSD的一个框架图,首先SSD获取目标位置和类别的方法跟YOLO一样,都是使用回归,但是YOLO预测某个位置使用的是全图的特征,SSD预测某个位置使用的是这个位置周围的特征(感觉更合理一些)。那么如何建立某个位置和其特征的对应关系呢?可能你已经想到了,使用Faster R-CNN的anchor机制。如SSD的框架图所示,假如某一层特征图(图b)大小是8*8,那么就使用3*3的滑窗提取每个位置的特征,然后这个特征回归得到目标的坐标信息和类别信息(图c)。
不同于Faster R-CNN,这个anchor是在多个feature map上,这样可以利用多层的特征并且自然的达到多尺度(不同层的feature map 3*3滑窗感受野不同)。
小结:SSD结合了YOLO中的回归思想和Faster R-CNN中的anchor机制,使用全图各个位置的多尺度区域特征进行回归,既保持了YOLO速度快的特性,也保证了窗口预测的跟Faster R-CNN一样比较精准。SSD在VOC2007上mAP可以达到72.1%,速度在GPU上达到58帧每秒。
总结:YOLO的提出给目标检测一个新的思路,SSD的性能则让我们看到了目标检测在实际应用中真正的可能性。

