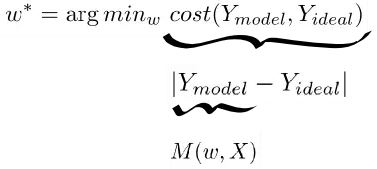选自Technica Curiosa
作者:Nishant Shukla
机器之心编译
参与:Jane W
本文的作者 Nishant Shukla 为加州大学洛杉矶分校的机器视觉研究者,从事研究赢咖4机器学习技术。Nishant Shukla 一直以来兼任 Microsoft、Facebook 和 Foursquare 的开发者,以及 SpaceX 的机器学习工程师。他还是《Haskell Data Analysis Cookbook》的作者。
还记得你小学时学习的科学课程吗?也许就在不久前,谁知道呢——也许你正在上小学,但是已经早早开始了你的机器学习之旅。不管是哪种方式,不管是生物、化学或者物理,一种分析数据的常用技术是用绘图来观察一个变量的变化对其它变量的影响。
设想你要绘制降雨频率与农作物产量间的相关性图。你也许会观察到随着降雨量的增加农业生产率也会增加。通过对这些数据拟合一条线,你可以预测不同降雨条件下的农业生产率。如果你能够从几个数据点发现隐式函数关系,那么你就可以利用此学习到的函数来预测未知数据的值。
回归算法研究的是如何最佳拟合概括数据的曲线。它是有监督学习算法中最强大和被研究最多的一类算法。在回归中,我们尝试通过找到可能生成数据的曲线来理解数据。通过这样做,我们为给定数据散点的分布原因找到了一种解释。最佳拟合曲线给出了一个解释数据集是如何生成的模型。
在本文中,你将学习如何用回归来解决一个实际问题。你将看到,如果你想拥有最强大的预测器,TensorFlow 工具将是正确的选择。
基本概念
如果你有工具,那么干什么事情都会很容易。我将演示第一个重要的机器学习工具——回归(regression),并给出精确的数学表达式。首先,你在回归中学习到的很多技能会帮助你解决可能遇到的其它类型的问题。读完本文,回归将成为你的机器学习工具箱中的得力工具。
假设我们的数据记录了人们在每瓶啤酒瓶上花多少钱。A 花了 2 美元 1 瓶,B 花了 4 美元 2 瓶,C 花了 6 美元 3 瓶。我们希望找到一个方程,能够描述啤酒的瓶数如何影响总花费。例如,如果每瓶啤酒都花费 2 美元,则线性方程 y=2x 可以描述购买特定数量啤酒的花费。
当一条线能够很好的拟合一些数据点时,我们可以认为我们的线性模型表现良好。实际上,我们可以尝试许多可能的斜率,而不是固定选择斜率值为 2。斜率为参数,产生的方程为模型。用机器学习术语来说,最佳拟合曲线的方程来自于学习模型的参数。
另一个例子,方程 y=3x 也是一条直线,除了具有更陡的斜率。你可以用任何实数替换该系数,这个系数称为 w,方程仍为一条直线:y=wx。图 1 显示了改变参数 w 如何影响模型。我们将这种方式生成的所有方程的集合表示为 M={ y=wx | w∈ℝ}。
这个集合表示「所有满足 y=wx 的方程,其中 w 是实数」。

图 1. 参数 w 的不同值代表不同的线性方程。所有这些线性方程的集合构成线性模型 M。
M 是所有可能的模型的集合。每选定一个 w 的值就会生成候选模型 M(w):y=wx。在 TensorFlow 中编写的回归算法将迭代收敛到更好的模型参数 w。我们称最佳参数为 w*,最佳拟合方程为 M(w*):y=w*x。
本质上,回归算法尝试设计一个函数(让我们将其称为 f),将输入映射到输出。函数的域是一个实数向量 ℝd,其范围是实数集 ℝ。函数的输入可以是连续的或离散的。然而,输出必须是连续的,如图 2 所示。
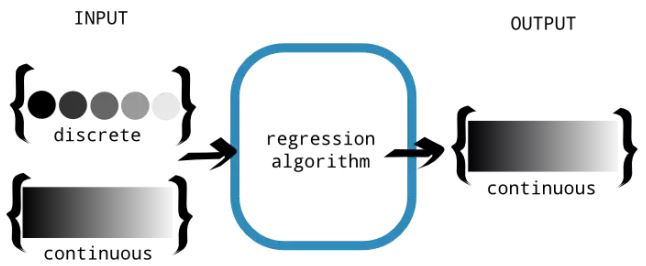
图 2. 回归算法是为了产生连续的输出。输入允许是离散的或连续的。这种区别是重要的,因为离散的输出值能更适合分类问题,我们将在下一章中讨论这个问题。
附带说明,回归的预测值为连续输出,但有时这是过度的。有时我们只想预测一个离散的输出,例如 0 或 1(0 和 1 之间不产生任何数值)。分类是一种更适合这类任务的技术。
我们希望找到与给定数据(即是输入/输出数据对)相一致的函数 f。不幸的是,可能的函数的数量是无限的,所以我们不能一个一个地尝试。有太多的选择通常并不是一件好事。需要缩小我们要处理的所有函数的范围。例如,若我们仅查找拟合数据的直线(不包含曲线),则搜索将变得更加容易。
练习 1:将 10 个整数映射到 10 个整数的所有可能函数有多少?例如,令 f(x) 是输入变量取数字 0 到 9 且输出为数字 0 到 9 的函数。例如模拟其输入的恒等函数(identity function),如 f(0)=0,f(1)=1,依此类推。还存在多少其它的函数?
答案:10^10=10000000000
如何判断回归算法可行?
假设我们正在向房地产公司兜售房地产市场预测算法。该算法在给定一些如卧室数量、公寓面积等房屋属性后能够预测房产的价格。房地产公司可以利用房价信息轻松地赚取数百万美元,但是在购买算法之前他们需要一些算法可行的证据。
衡量训练后的算法是否成功有两个重要指标:方差(variance)和偏差(bias)。
方差反映的是预测值对于训练集的敏感度(波动)。我们希望在理想情况下,训练集的选择对结果影响很小——意味着需要较小的方差值。
偏差代表了训练集假设的可信度。太多的假设可能会难以泛化,所以也需要较小的偏差值。
一方面,过于灵活的模型可能导致模型意外地记住训练集,而不是发现有用的模式特征。你可以想象一个弯曲的函数经过数据集的每个点而不产生错误。如果发生这种情况,我们说学习算法对训练数据过拟合。在这种情况下,最佳拟合曲线将很好地拟合训练数据;然而,当用测试集进行评估时,结果可能非常糟糕(参见图 3)。

图 3. 理想情况下,最佳拟合曲线同时适用于训练集和测试集。然而,如果看到测试集的表现比训练集更好,那么我们的模型有可能欠拟合。相反,如果在测试集上表现不佳,而对训练集表现良好,那么我们的模型是过拟合的。
另一方面,不那么灵活的模型可以更好地概括未知的测试数据,但是在训练集上表现欠佳。这种情况称为欠拟合。一个过于灵活的模型具有高方差和低偏差,而一个不灵活的模型具有低方差和高偏差。理想情况下,我们想要一个具有低方差误差和低偏差误差的模型。这样一来,它们就能够概括未知的数据并捕获数据的规律性。参见图 4 的例子。
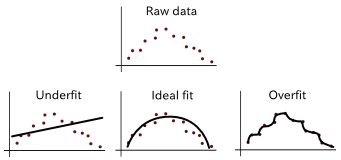
图 4. 数据欠拟合和过拟合的例子。
具体来说,模型的方差是衡量响应的波动程度有多大的一个标准,偏差是响应与实际数据相差的程度。最后,希望模型达到准确(低偏差)和可重复(低方差)的效果。
练习 2:假设我们的模型为 M(w):y=wx。如果权重 w 的值必须为 0-9 之间的整数,则有多少个可能的函数?
答案:只有 10 种情况,即 { y=0,y=x,y=2x,...,y=9x }。
为了评估机器学习模型,我们将数据集分为两组:训练集和测试集。训练集用来学习模型,测试集用来评估性能。存在很多可能的权重参数,但我们的目标是找到最适合数据的权重。用来衡量「最适合」的方式是定义成本函数(cost function)。
线性回归
让我们利用模拟数据来进行线性回归。创建一个名为 regression.py 的 Python 源文件,并按照列表 1 初始化数据。代码将产生类似于图 5 的输出。
列表 1:可视化原始输入
import numpy as np //#Aimport matplotlib.pyplot as plt //#B x_train = np.linspace(-1, 1, 101) //#C y_train = 2 * x_train + np.random.randn(*x_train.shape) * 0.33 //#D plt.scatter(x_train, y_train) //#E plt.show() //#E
# A:导入 NumPy 包,用来生成初始化的原始数据
# B:使用 matplotlib 可视化数据
# C:输入值为 -1 到 1 之间的 101 个均匀间隔的数字
# D:生成输出值,与输入值成正比并附加噪声
# E:使用 matplotlib 的函数绘制散点图
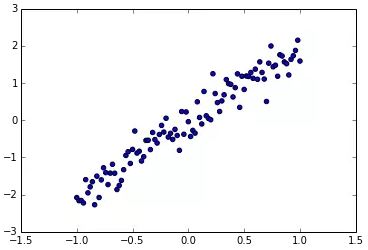
图 5. 散点图 y=x+ε,ε 为噪声。
现在你可以利用这些数据点尝试拟合一条直线。在 TensorFlow 中,你至少需要为尝试的每个候选参数打分。该打分通常称为成本函数。成本函数值越高,模型参数越差。例如,如果最佳拟合直线为 y=2x,选择参数值为 2.01 时应该有较低的成本函数值,但是选择参数值为 -1 时应该具有较高的成本函数值。
这时,我们的问题就转化为最小化成本函数值,如图 6 所示,TensorFlow 试图以有效的方式更新参数,并最终达到最佳的可能值。每个更新所有参数的步骤称为 epoch。