在听到人们谈论机器学习的时候,你是不是对它的涵义只有几个模糊的认识呢?你是不是已经厌倦了在和同事交谈时只能一直点头?让我们改变一下吧!
本指南的读者对象是所有对机器学习有求知欲但却不知道如何开头的朋友。我猜很多人已经读过了“机器学习”的维基百科词条,倍感挫折,以为没人能给出一个高层次的解释。本文就是你们想要的东西。
本文目标在于平易近人,这意味着文中有大量的概括。但是谁在乎这些呢?只要能让读者对于ML更感兴趣,任务也就完成了。
何为机器学习?
机器学习这个概念认为,对于待解问题,你无需编写任何专门的程序代码,泛型算法(generic algorithms)能够在数据集上为你得出有趣的答案。对于泛型算法,不用编码,而是将数据输入,它将在数据之上建立起它自己的逻辑。
举个例子,有一类算法称为分类算法,它可以将数据划分为不同的组别。一个用来识别手写数字的分类算法,不用修改一行代码,就可以用来将电子邮件分为垃圾邮件和普通邮件。算法没变,但是输入的训练数据变了,因此它得出了不同的分类逻辑。
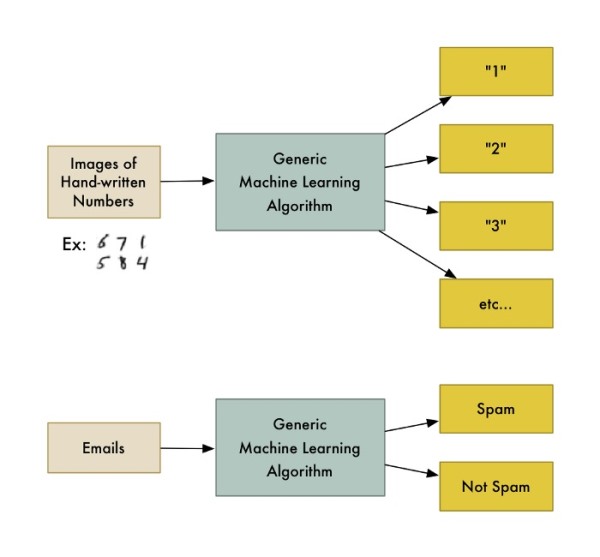
机器学习算法是个黑盒,可以重用来解决很多不同的分类问题。
“机器学习”是一个涵盖性术语,覆盖了大量类似的泛型算法。
两类机器学习算法
你可以认为机器学习算法分为两大类:监督式学习(Supervised Learning)和非监督式学习(Unsupervised Learning)。两者区别很简单,但却非常重要。
监督式学习
假设你是一名房产经纪,生意越做越大,因此你雇了一批实习生来帮你。但是问题来了——你可以看一眼房子就知道它到底值多少钱,实习生没有经验,不知道如何估价。
为了帮助你的实习生(也许是为了解放你自己去度个假),你决定写个小软件,可以根据房屋大小、地段以及类似房屋的成交价等因素来评估你所在地区房屋的价值。
你把3个月来城里每笔房屋交易都写了下来,每一单你都记录了一长串的细节——卧室数量、房屋大小、地段等等。但最重要的是,你写下了最终的成交价:
这是我们的“训练数据”。

我们要利用这些训练数据来编写一个程序来估算该地区其他房屋的价值:

这就称为监督式学习。你已经知道每一栋房屋的售价,换句话说,你知道问题的答案,并可以反向找出解题的逻辑。
为了编写软件,你将包含每一套房产的训练数据输入你的机器学习算法。算法尝试找出应该使用何种运算来得出价格数字。
这就像是算术练习题,算式中的运算符号都被擦去了:


