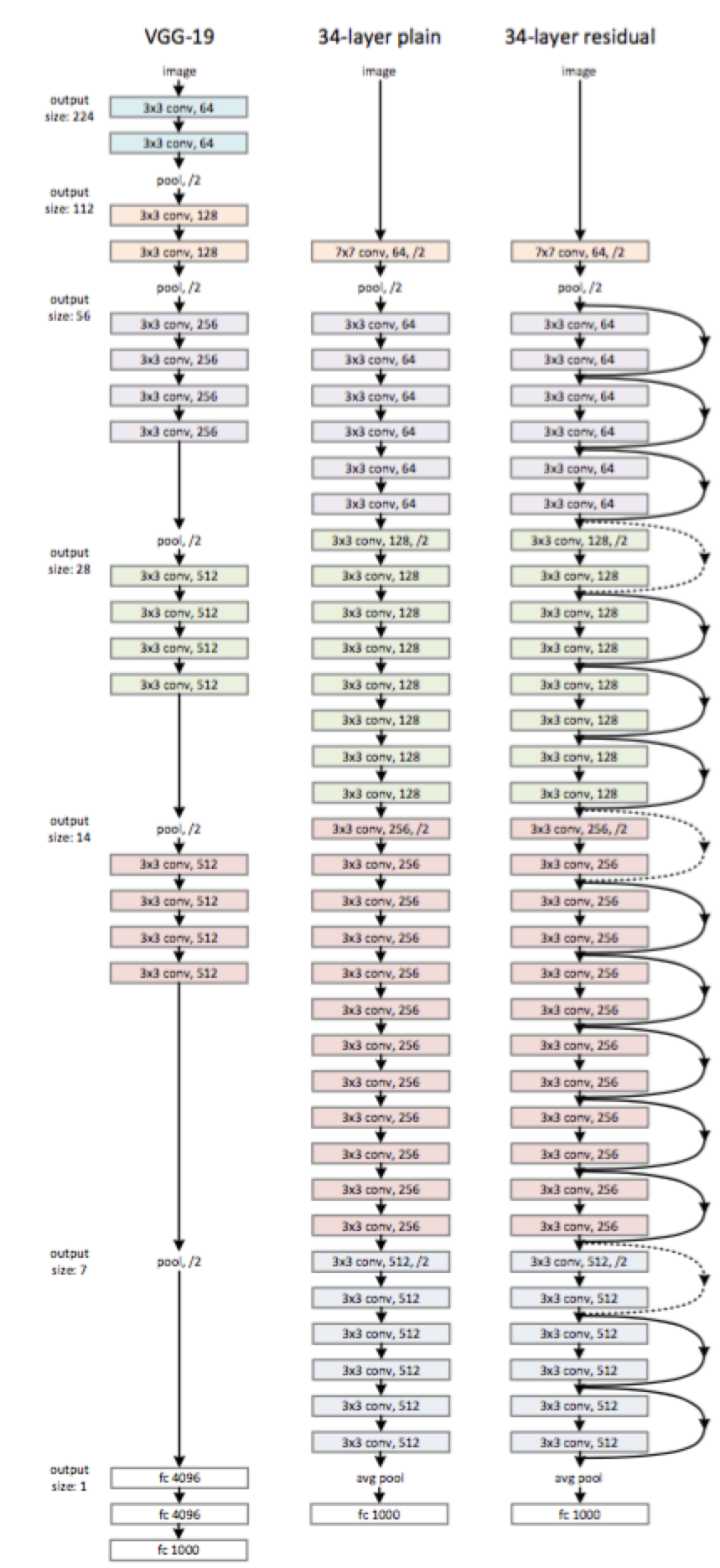
Deep Residual Network
Deep Residual Network解读
一般来说越深的网络,越难被训练,Deep Residual Learning for Image Recognition中提出一种residual learning的框架,能够大大简化模型网络的训练时间,使得在可接受时间内,模型能够更深(152甚至尝试了1000),该方法在ILSVRC2015上取得最好的成绩。
随着模型深度的增加,会产生以下问题:
- vanishing/exploding gradient,导致了训练十分难收敛,这类问题能够通过norimalized initialization 和intermediate normalization layers解决;
- 对合适的额深度模型再次增加层数,模型准确率会迅速下滑(不是overfit造成),training error和test error都会很高,相应的现象在CIFAR-10和ImageNet都有提及
为了解决因深度增加而产生的性能下降问题,作者提出下面一种结构来做residual learning:

假设潜在映射为H(x),使stacked nonlinear layers去拟合F(x):=H(x)-x,残差优化比优化H(x)更容易。
F(x)+x能够很容易通过”shortcut connections”来实现。
这篇文章主要得改善就是对传统的卷积模型增加residual learning,通过残差优化来找到近似最优identity mappings。
paper当中的一个网络结构: