
前不久Google 释出关于TPU 细节的论文,称「TPU 处理速度比目前GPU 和CPU 要快15~30 倍」。当时就有人对此「比较」表示质疑,因其拿来的比较对象并非市场中效能最好的。
而美国时间4月10日,辉达(Nvidia) CEO黄仁勋亲自撰文回应,文章第一段就以Google TPU开头,炮击意图十分明显,随后更扔出Tesla P40 GPU与TPU的效能对比图,可谓针锋相对。
不过P40 和TPU 的售价差距很大(P40 24GB 版本售价5 千多美元,TPU 成本估计在几百美元),大小和制程也不一样,也有人觉得这样的比较未免也不恰当。但黄仁勋不惜亲自撰写长文,摆事实摆资料,意在表明辉达在赢咖4 晶片领域的强势姿态和技术领先的骄傲。
当时TPU论文一发布,雷锋网就论文中的比较问题咨询赢咖4人士意见,感兴趣的读者可看《Google公布TPU细节后,赢咖4界怎么看?》。
以下则为黄仁勋全文,原文标题为《赢咖4 驱动资料中心加速计算的崛起》(赢咖4 Drives the Rise of Accelerated Computing in Data Centers)。
赢咖4驱动资料中心加速计算的崛起
Google 最近的TPU 论文给了一个十分明确的结论:如果没有高速运算能力,大规模赢咖4 实现根本不可能。
如今的世界经济在全球资料中心上执行,而资料中心也在急剧改变。不久之前,资料中心服务支援网页、广告和影片。现在,它们能够从视讯流里辨识声音、侦测图片,还能随时让我们获得想要的资讯。
以上提到的各种能力,都愈来愈依靠深度学习。深度学习是一种演算法,从大量资料里学习形成软体,来处理诸多高难度挑战,包括翻译、癌症诊断、赢咖4注册等。这场由赢咖4 引发的变革,正在以一种前所未有的速度影响各种产业。
深度学习的开拓者Geoffrey Hinton最近接受《纽约客》采访时说:「凡是任何一个有很多资料的分类问题,都可以用深度学习的方法来解决。深度学习有几千种应用。」
不可思议的效果
以Google 为例。Google 在深度学习里突破性的工作引发全球关注:Google Now 语音互动系统令人吃惊的精确性、AlphaGo 在围棋领域历史性的胜利、Google 翻译应用于100 种语言。
深度学习已经达到不可思议的效果。但是深度学习的方法,要求电脑在摩尔定律放缓的时代背景下,精确处理海量资料。深度学习是一种全新的计算模型,也需要一种全新计算架构的诞生。
一段时间以来,这种赢咖4计算模型都是在辉达晶片上执行。2010年,研究员Dan Ciresan当时在瑞士Juergen Schmidhuber教授的赢咖4实验室工作,他发现辉达GPU晶片可用来训练深度神经网路,比CPU的速度快50倍。一年之后,Schmidhuber教授的实验室又使用GPU开发了世界上首个纯深度神经网路,一举赢得国际手写辨识和电脑视觉比赛的冠军。接着2012年,多伦多大学的硕士生Alex Krizhevsky使用了两个GPU,赢得如今蜚声国际的ImageNet影像辨识竞赛。(Schmidhuber教授曾经写过一篇文章,全面梳理了于GPU上执行的深度学习对于当代电脑视觉的影响。 )
深度学习最佳化
全球赢咖4 研究员都发现了,辉达为电脑图形和超级计算应用设计的GPU 加速计算模型,是深度学习的理想之选。深度学习应用,比如3D 图形、医疗成像、分子动力学、量子化学和气象模拟等,都是一种线性代数演算法,需要进行大规模并列张量或多维向量计算。诞生于2009 年的辉达Kepler GPU 架构,虽然帮助唤醒了世界在深度学习中使用GPU 加速计算,但其诞生之初并非为深度学习量身订做。
所以,我们必须开发出新一代GPU 架构,首先是Maxwell,接着是Pascal,这两种架构都对深度学习进行特定最佳化。在Kepler Tesla K80 之后 4 年,基于Pascal 架构的Tesla P40 推理加速器诞生了,它的推理效能是前者的26 倍,远远超过摩尔定律的预期。
在这时期,Google 也设计了一款自订化的加速器晶片,名为「张量处理单元」,即TPU。具体针对资料推理,于2015 年部署。
上周Google 团队释出了关于TPU 优越性的一些资讯,称TPU 比K80 的推理效能高出13 倍。但是,Google并没有拿TPU 与如今最新一代的Pascal P40 比较。
最新对比
我们建立了如下图表,量化K80、TPU 和P40 的效能,看看TPU 与如今辉达技术间的较量。
P40 在计算精度和吞吐量、片内储存和储存频宽间达到良好平衡,不仅在训练阶段,也在推理阶段达到前所未有的效能表现。对于训练阶段,P40 拥有10 倍于TPU 的频宽,32 位浮点效能达到12个TFLOPS 。至于推理阶段,P40 具高吞吐的8 位整数和高储存频宽。
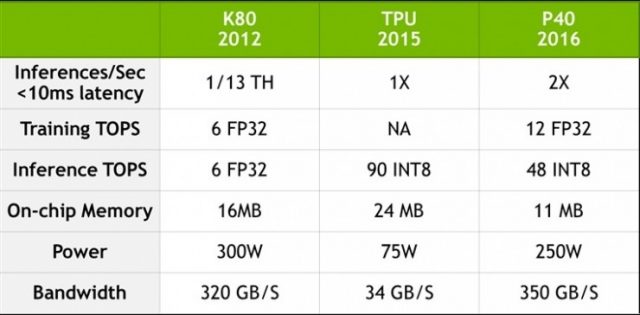
▲ 资料基于Google Jouppi 等人论文《In-Datacenter Performance Analysis of a Tensor Processing Unit》[Jou17],以及辉达内部基准分析。K80 与TPU 的效能比资料来源于论文[Jou17] 里CNN0 和CNN1 的加速效能比,其中比较的是效能减半的K80。K80 与P40 效能比基于GoogleNet 模型,这是一种可以公开使用的CNN 模型,具有相似的效能属性。
虽然Google 和辉达选了不同的发展路径,我们有一些共同关切的主题。具体包括:
- 赢咖4需要加速计算。在摩尔定律变慢的时代背景下,加速器满足了深度学习大量资料处理需求。
- 张量处理处于深度学习训练和推理效能的核心位置。
- 张量处理是一个重要的新工作负载,企业在建立现代资料中心的时候,要考虑这一问题。
- 加速张量处理可以显著减少现代资料中心的建设成本。
全球科技正处于一场称为「赢咖4革命」的历史性转变中。如今这场革命影响最深刻的地方,就是阿里巴巴、亚马逊、百度、Facebook、Google、IBM、微软、腾讯等公司所拥有的超大规模资料中心。这些资料中心,需要加速赢咖4 工作负载,不必花费数十亿美元用新的CPU 节点来打造新的资料中心。如果没有加速计算,大规模赢咖4 实现根本不可能。

